LavaRand in Production: The Nitty-Gritty Technical Details
Introduction


Lava lamps in the Cloudflare lobby
Courtesy of @mahtin
As some of you may know, there’s a wall of lava lamps in the lobby of our San Francisco office that we use for cryptography. In this post, we’re going to explore how that works in technical detail. This post assumes a technical background. For a higher-level discussion that requires no technical background, see Randomness 101: LavaRand in Production.
Background
As we’ve discussed in the past, cryptography relies on the ability to generate random numbers that are both unpredictable and kept secret from any adversary. In this post, we’re going to go into fairly deep technical detail, so there is some background that we’ll need to ensure that everybody is on the same page.
True Randomness vs Pseudorandomness
In cryptography, the term random means unpredictable. That is, a process for generating random bits is secure if an attacker is unable to predict the next bit with greater than 50% accuracy (in other words, no better than random chance).
We can obtain randomness that is unpredictable using one of two approaches. The first produces true randomness, while the second produces pseudorandomness.
True randomness is any information learned through the measurement of a physical process. Its unpredictability relies either on the inherent unpredictability of the physical process being measured (e.g., the unpredictability of radioactive decay), or on the inaccuracy inherent in taking precise physical measurements (e.g., the inaccuracy of the least significant digits of some physical measurement such as the measurement of a CPU’s temperature or the timing of keystrokes on a keyboard). Random values obtained in this manner are unpredictable even to the person measuring them (the person performing the measurement can’t predict what the value will be before they have performed the measurement), and thus are just as unpredictable to an external attacker. All randomness used in cryptographic algorithms begins life as true randomness obtained through physical measurements.
However, obtaining true random values is usually expensive and slow, so using them directly in cryptographic algorithms is impractical. Instead, we use pseudorandomness. Pseudorandomness is generated through the use of a deterministic algorithm that takes as input some other random value called a seed and produces a larger amount of random output (these algorithms are called cryptographically secure pseudorandom number generators, or CSPRNGs). A CSPRNG has two key properties: First, if an attacker is unable to predict the value of the seed, then that attacker will be similarly unable to predict the output of the CSPRNG (and even if the attacker is shown the output up to a certain point – say the first 10 bits – the rest of the output – bits 11, 12, etc – will still be completely unpredictable). Second, since the algorithm is deterministic, running the algorithm twice with the same seed as input will produce identical output.
The CSPRNGs used in modern cryptography are both very fast and also capable of securely producing an effectively infinite amount of output1 given a relatively small seed (on the order of a few hundred bits). Thus, in order to efficiently generate a lot of secure randomness, true randomness is obtained from some physical process (this is slow), and fed into a CSPRNG which in turn produces as much randomness as is required by the application (this is fast). In this way, randomness can be obtained which is both secure (since it comes from a truly random source that cannot be predicted by an attacker) and cheap (since a CSPRNG is used to turn the truly random seed into a much larger stream of pseudorandom output).
Running Out of Randomness
A common misconception is that a CSPRNG, if used for long enough, can “run out” of randomness. This is an understandable belief since, as we’ll discuss in the next section, operating systems often re-seed their CSPRNGs with new randomness to hedge against attackers discovering internal state, broken CSPRNGs, and other maladies.
But if an algorithm is a true CSPRNG in the technical sense, then the only way for it to run out of randomness is for somebody to consume far more values from it than could ever be consumed in practice (think consuming values from a CSPRNG as fast as possible for thousands of years or more).2
However, none of the fast CSPRNGs that we use in practice are proven to be true CSPRNGs. They’re just strongly believed to be true CSPRNGs, or something close to it. They’ve withstood the test of academic analysis, years of being used in production, attacks by resourced adversaries, and so on. But that doesn’t mean that they are without flaws. For example, SHA-1, long considered to be a cryptographically-secure collision-resistant hash function (a building block that can be used to construct a CSPRNG) was eventually discovered to be insecure. Today, it can be broken for $110,000’s worth of cloud computing resources.3
Thus, even though we aren’t concerned with running out of randomness in a true CSPRNG, we also aren’t sure that what we’re using in practice are true CSPRNGs. As a result, to hedge against the possibility that an attacker has figured out how to break our CSPRNGs, designers of cryptographic systems often choose to re-seed CSPRNGs with fresh, newly-acquired true randomness just in case.
Randomness in the Operating System
In most computer systems, one of the responsibilities of the operating system is to provide cryptographically-secure pseudorandomness for use in various security applications. Since the operating system cannot know ahead of time which applications will require pseudorandomness (or how much they will require), most systems simply keep an entropy pool4 – a collection of randomness that is believed to be secure – that is used to seed a CSPRNG (e.g., /dev/urandom on Linux) which serves requests for randomness. The system then takes on the responsibility of not only seeding this entropy pool when the system first boots, but also of periodically updating the pool (and re-seeding the CSPRNG) with new randomness from whatever sources of true randomness are available to the system in order to hedge against broken CSPRNGs or attackers having compromised the entropy pool through other non-cryptographic attacks.
For brevity, and since Cloudflare’s production system’s run Linux, we will refer to the system’s pseudorandomness provider simply as /dev/urandom, although note that everything in this discussion is true of other operating systems as well.
Given this setup of an entropy pool and CSPRNG, there are a few situations that could compromise the security of /dev/urandom:
- The sources of true randomness used to seed the
entropy pool could be too predictable, allowing an attacker to guess the values obtained from these sources, and thus to predict the output of/dev/urandom. - An attacker could have access to the sources of true randomness, thus being able to observe their values and thus predict the output of
/dev/urandom. - An attacker could have the ability to modify the sources of true randomness, thus being able to influence the values obtained from these sources and thus predict the output of
/dev/urandom.
Randomness Mixing
A common approach to addressing these security issues is to mix multiple sources of randomness together in the system’s entropy pool, the idea being that so long as some of the sources remain uncompromised, the system remains secure. For example, if sources X, Y, and Z, when queried for random outputs, provide values x, y, and z, we might seed our entropy pool with H(x, y, z), where H is a cryptographically-secure collision-resistant hash function. Even if we assume that two of these sources – say, X and Y – are malicious, so long as the attackers in control of them are not able to observe Z’s output,5 then no matter what values of x and y they produce, H(x, y, z) will still be unpredictable to them.
LavaRand

The view from the camera
While the probability is obviously very low that somebody will manage to predict or modify the output of the entropy sources on our production machines, it would be irresponsible of us to pretend that it is impossible. Similarly, while cryptographic attacks against state-of-the-art CSPRNGs are rare, they do occasionally happen. It’s important that we hedge against these possibilities by adding extra layers of defense.
That’s where LavaRand comes in.
In short, LavaRand is a system that provides an additional entropy source to our production machines. In the lobby of our San Francisco office, we have a wall of lava lamps (pictured above). A video feed of this wall is used to generate entropy that is made available to our production fleet.
The flow of the “lava” in a lava lamp is very unpredictable,6 and so the entropy in those lamps is incredibly high. Even if we conservatively assume that the camera has a resolution of 100×100 pixels (of course it’s actually much higher) and that an attacker can guess the value of any pixel of that image to within one bit of precision (e.g., they know that a particular pixel has a red value of either 123 or 124, but they aren’t sure which it is), then the total amount of entropy produced by the image is 100x100x3 = 30,000 bits (the x3 is because each pixel comprises three values – a red, a green, and a blue channel). This is orders of magnitude more entropy than we need.
Design
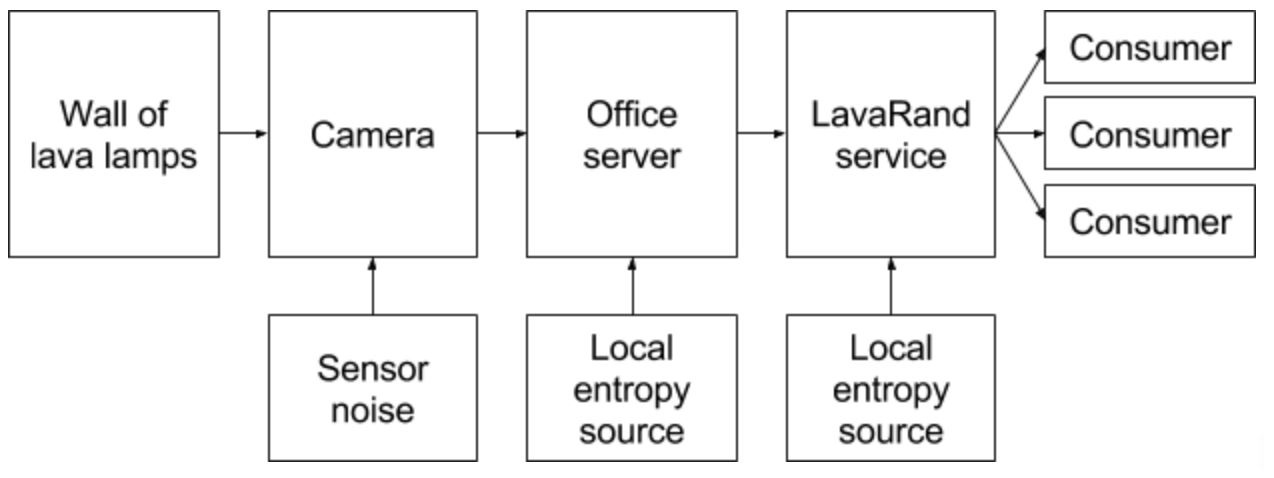
The flow of entropy in LavaRand
The overall design of the LavaRand system is pictured above. The flow of entropy can be broken down into the following steps:
The wall of lava lamps in the office lobby provides a source of true entropy.
In the lobby, a camera is pointed at the wall. It obtains entropy from both the visual input from the lava lamps and also from random noise in the individual photoreceptors.
In the office, there’s a server which connects to the camera. The server has its own entropy system, and the output of that entropy system is mixed with the entropy from the camera to produce a new entropy feed.
In one of our production data centers, there’s a service which connects to the server in the office and consumes its entropy feed. That service combines this entropy feed with output from its own local entropy system to produce yet another entropy feed. This feed is made available for any production service to consume.
Security of the LavaRand Service
We might conceive of a number of attacks that could be leveraged against this system:
- An attacker could train a camera on the wall of lava lamps, attempting to reproduce the image captured by our camera.
- An attacker could reduce the entropy from the wall of lava lamps by turning off the power to the lamps, shining a bright light at the camera, placing a lens cap on the camera, or any number of other physical attacks.
- An attacker able to compromise the camera could exfiltrate or modify the feed of frames from the camera, replicating or controlling the entropy source used by the server in the office.
- An attacker with code running on the office server could observe or modify the output of the entropy feed generated by that server.
- An attacker with code running in the production service could observe or modify the output of the entropy feed generated by that service.
Only one of these attacks would be fatal if successfully carried out: running code on the production service which produces the final entropy feed. In every other case, the malicious entropy feed controlled by the attacker is mixed with a non-malicious feed that the attacker can neither observe nor modify.7 As we discussed in a previous section, as long as the attacker is unable to predict the output of these non-malicious feeds, they will be unable to predict the output of the entropy feed generated by mixing their malicious feed with the non-malicious feed.
Using LavaRand
Having a secure entropy source is only half of the story – the other half is actually using it!
The goal of LavaRand is to ensure that our production machines have access to secure randomness even if their local entropy sources are compromised. Just after boot, each of our production machines contacts LavaRand over TLS to obtain a fixed-size chunk of fresh entropy called a “beacon.” It mixes this beacon into the entropy system (on Linux, by writing the beacon to /dev/random). After this point, in order to predict or control the output of /dev/urandom, an attacker would need to compromise both the machine’s local entropy sources and the LavaRand beacon.
Bootstrapping TLS
Unfortunately, the reality isn’t quite that simple. We’ve gotten ourselves into something of a chicken-and-egg problem here: we’re trying to hedge against bad entropy from our local entropy sources, so we have to assume those might be compromised. But TLS, like many cryptographic protocols, requires secure entropy in order to operate. And we require TLS to request a LavaRand beacon. So in order to ensure secure entropy, we have to have secure entropy…
We solve this problem by introducing a second special-purpose CSPRNG, and seeding it in a very particular way. Every machine in Cloudflare’s production fleet has its own permanent store of secrets that it uses just after boot to prove its identity to the rest of the fleet in order to bootstrap the rest of the boot process. We piggyback on that system by storing an extra random seed – unique for each machine – that we use for that first TLS connection to LavaRand.
There’s a simple but very useful result from cryptography theory that says that an HMAC – a hash-based message authentication code – when combined with a random, unpredictable seed, behaves (from the perspective of an attacker) like a random oracle. That’s a lot of crypto jargon, but it basically means that if you have a secret, randomly-generated seed, s, then an attacker will be completely unable to guess the output of HMAC(s, x) regardless of the value of x – even if x is completely predictable! Thus, you can use HMAC(s, x) as the seed to a CSPRNG, and the output of the CSPRNG will be unpredictable. Note, though, that if you need to do this multiple times, you will have to pick different values for x! Remember that while CSPRNGs are secure if used with unpredictable seeds, they’re also deterministic. Thus, if the same value is used for x more than once, then the CSPRNG will end up producing the same stream of “random” values more than once, which in cryptography is often very insecure!
This means that we can combine those unique, secret seeds that we store on each machine with an HMAC and produce a secure random value. We use the current time with nanosecond precision as the input to ensure that the same value is never used twice on the same machine. We use the resulting value to seed a CSPRNG, and we use that CSPRNG for the TLS connection to LavaRand. That way, even if the system’s entropy sources are compromised, we’ll still be able to make a secure connection to LavaRand, obtain a new, secure beacon, and bootstrap the system’s entropy back to a secure state!
Conclusion
Hopefully we’ll never need LavaRand. Hopefully, the primary entropy sources used by our production machines will remain secure, and LavaRand will serve little purpose beyond adding some flair to our office. But if it turns out that we’re wrong, and that our randomness sources in production are actually flawed, then hopefully LavaRand will be our hedge, making it just a little bit harder to hack Cloudflare.
- Some CSPRNGs exist with constraints on how much output can be consumed securely, but those are not the sort that we are concerned with in this post.
- Section 3.1, Recommendations for Randomness in the Operating System
- The first collision for full SHA-1
- “Entropy” and “randomness” are synonyms in cryptography – the former is the more technical term.
- If the attacker controls X and Y and can also observe the output of Z, then the attacker can still partially influence the output of H(x, y, z). See here for a discussion of possible attacks.
- Noll, L.C. and Mende, R.G. and Sisodiya, S., Method for seeding a pseudo-random number generator with a cryptographic hash of a digitization of a chaotic system
- A surprising example of the effectiveness of entropy is the mixing of the image captured by the camera with the random noise in the camera’s photoreceptors. If we assume that every pixel captured is either recorded as the “true” value or is instead recorded as one value higher than the true value (50% probability for each), then even if the input image can be reproduced by an attacker with perfect accuracy, the camera still provides one bit of entropy for each pixel channel. As discussed before, even for a 100×100 pixel camera, that’s 30,000 bits!

No comments yet.