Privacy Pass – “The Math”
This is a guest post by Alex Davidson, a PhD student in Cryptography at Royal Holloway, University of London, who is part of the team that developed Privacy Pass. Alex worked at Cloudflare for the summer on deploying Privacy Pass on the Cloudflare network.
During a recent internship at Cloudflare, I had the chance to help integrate support for improving the accessibility of websites that are protected by the Cloudflare edge network. Specifically, I helped develop an open-source browser extension named ‘Privacy Pass’ and added support for the Privacy Pass protocol within Cloudflare infrastructure. Currently, Privacy Pass works with the Cloudflare edge to help honest users to reduce the number of Cloudflare CAPTCHA pages that they see when browsing the web. However, the operation of Privacy Pass is not limited to the Cloudflare use-case and we envisage that it has applications over a wider and more diverse range of applications as support grows.
In summary, this browser extension allows a user to generate cryptographically ‘blinded’ tokens that can then be signed by supporting servers following some receipt of authenticity (e.g. a CAPTCHA solution). The browser extension can then use these tokens to ‘prove’ honesty in future communications with the server, without having to solve more authenticity challenges.
The ‘blind’ aspect of the protocol means that it is infeasible for a server to link tokens token that it signs to tokens that are redeemed in the future. This means that a client using the browser extension should not compromise their own privacy with respect to the server they are communicating with.
In this blog post we hope to give more of an insight into how we have developed the protocol and the security considerations that we have taken into account. We have made use of some interesting and modern cryptographic techniques that we believe could have a future impact on a wide array of problems.
Previously…
The research team released a specification last year for a “blind signing” protocol (very similar to the original proposal of Chaum using a variant of RSA known as ‘blind RSA’. Blind RSA simply uses the homomorphic properties of the textbook RSA signature scheme to allow the user to have messages signed obliviously. Since then, George Tankersley and Filippo Valsorda gave a talk at Real World Crypto 2017 explaining the idea in more detail and how the protocol could be implemented. The intuition behind a blind signing protocol is also given in Nick’s blog post.
A blind signing protocol between a server A and a client B roughly takes the following form:
- B generates some value
tthat they require a signature from A for. - B calculates a ‘blinded’ version of
tthat we will callbt - B sends
btto A - A signs
btwith their secret signing key and returns a signaturebzto B - B receives
bzand ‘unblinds’ to receive a signaturezfor valuet.
Due to limitations arising from the usage of RSA (e.g. large signature sizes, slower operations), there were efficiency concerns surrounding the extra bandwidth and computation time on the client browser. Fortunately, we received a lot of feedback from many notable individuals (full acknowledgments below). In short, this helped us to come up with a protocol with much lower overheads in storage, bandwidth and computation time using elliptic curve cryptography as the foundation instead.
Elliptic curves (a very short introduction)
An elliptic curve is defined over a finite field modulo some prime p. Briefly, an (x,y) coordinate is said to lie on the curve if it satisfies the following equation:
y^2 = x^3 + a*x + b (modulo p)
Nick Sullivan wrote an introductory blog post on the use of elliptic curves in cryptography a while back, so this may be a good place to start if you’re new to the area.
Elliptic curves have been studied for use in cryptography since the independent works of Koblitz and Miller (1984-85). However, EC-based ciphers and signature algorithms have rapidly started replacing older primitives in the Internet-space due to large improvements in the choice of security parameters available. What this translates to is that encryption/signing keys can be much smaller in EC cryptography when compared to more traditional methods such as RSA. This comes with huge efficiency benefits when computing encryption and signing operations, thus making EC cipher suites perfect for use on an Internet-wide scale.
Importantly, there are many different elliptic curve configurations that are defined by the choice of p, a and b for the equation above. These prevent different security and efficiency benefits; some have been standardized by NIST. In this work, we will be using the NIST specified P256 curve, however, this choice is largely agnostic to the protocol that we have designed.
Blind signing via elliptic curves
Translating our blind signing protocol from RSA to elliptic curves required deriving a whole new protocol. Some of the suggestions pointed out cryptographic constructions known as “oblivious pseudorandom functions”. A pseudorandom function or PRF is a mainstay of the traditional cryptographic arsenal and essentially takes a key and some string as input and outputs some cryptographically random value.
Let F be our PRF, then the security requirement on such a function is that evaluating:
y = F(K,x)
is indistinguishable from evaluating:
y’ = f(x)
where f is a randomly chosen function with outputs defined in the same domain as F(K,-). Choosing a function f at random undoubtedly leads to random outputs, however for F, randomness is derived from the choice of key K. In practice, we would instantiate a PRF using something like HMAC-SHA256.
Oblivious PRFs
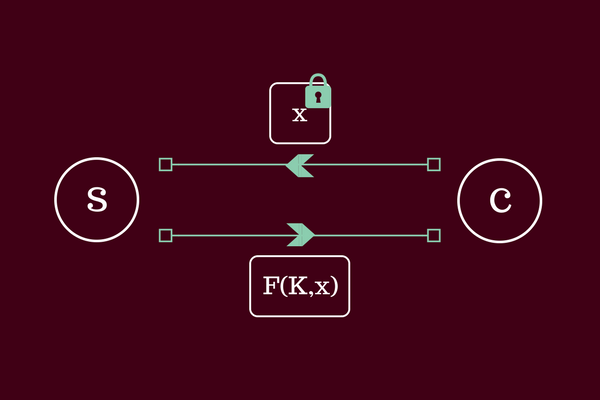
An oblivious PRF (OPRF) is actually a protocol between a server S and a client C. In the protocol, S holds a key K for some PRF F and C holds an input x. The security goal is that C receives the output y = F(K,x) without learning the key K and S does not learn the value x.
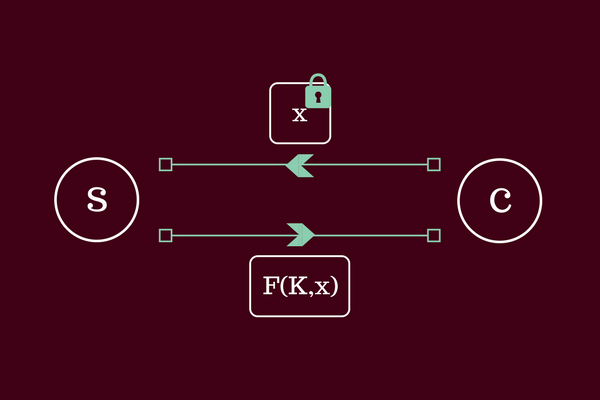
It may seem difficult to construct such a functionality without revealing the input x or the key K. However, there are numerous (and very efficient) constructions of OPRFs with applications to many different cryptographic problems such as private set intersection, password-protected secret-sharing and cryptographic password storage to name a few.
OPRFs from elliptic curves
A simple instantiation of an OPRF from elliptic curves was given by Jarecki et al. JKK14, we use this as the foundation for our blind signing protocol.
- Let
Gbe a cyclic group of prime-order - Let
Hbe a collision-resistant hash function hashing intoG - Let
kbe a private key held by S - Let
xbe a private input held by C
The protocol now proceeds as:
- C sends
H(x)to S - S returns
kH(x)to C
Clearly, this is an exceptionally simple protocol, security is established since:
- The collision-resistant hash function prevents S from reversing
H(x)to learnx - The hardness of the discrete log problem (DLP) prevents C from learning
kfromkH(x) - The output
kH(x)is pseudorandom sinceGis a prime-order group andkis chosen at random.
Blind signing via an OPRF
Using the OPRF design above as the foundation, the research team wrote a variation that we can use for a blind signing protocol; we detail this construction below. In our ‘blind signing’ protocol we require that:
- The client/user can have random values signed obliviously by the edge server
- The client can ‘unblind’ these values and present them in the future for verification
- The edge can commit to the secret key publicly and prove that it is used for signing all tokens globally
The blind signing protocol is split into two phases.
Firstly, there is a blind signing phase that is carried out between the user and the edge after the user has successfully solved a challenge. The result is that the user receives a number of signed tokens (default 30) that are unblinded and stored for future use. Intuitively, this mirrors the execution of the OPRF protocol above.
Secondly, there is a redemption phase where an unblinded token is used for bypassing a future iteration of the challenge.
Let G be a cyclic group of prime-order q. Let H_1,H_2 be a pair of collision-resistant hash functions; H_1 hashes into the group G as before, H_2 hashes into a binary string of length n.
In the following, we will slightly different notation to make it consistent with existing literature. Let x be a private key held by the server S. Let t be the input held by the user/client C. Let ZZ_q be the ring of integers modulo q. We write all operations in their scalar multiplication form to be consistent with EC notation. Let MAC_K() be a message-authentication code algorithm keyed by a key K.
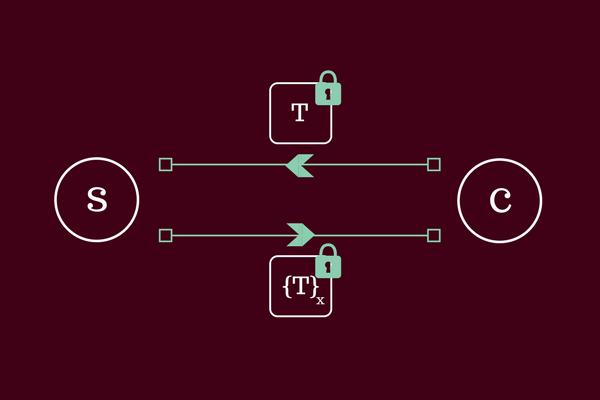
Signing phase
- C samples a random ‘blind’
r ← ZZ_q - C computes
T = H_1(t)and then blinds it by computingrT - C sends
M = rTto S - S computes
Z = xMand returnsZto C - C computes
(1/r)*Z = xT = Nand stores the pair(t,N)for some point in the future
We think of T = H_1(t) as a token, these objects form the backbone of the protocol that we use to bypass challenges.
Notice, that the only difference between this protocol and the OPRF above is the blinding factor r that we use.
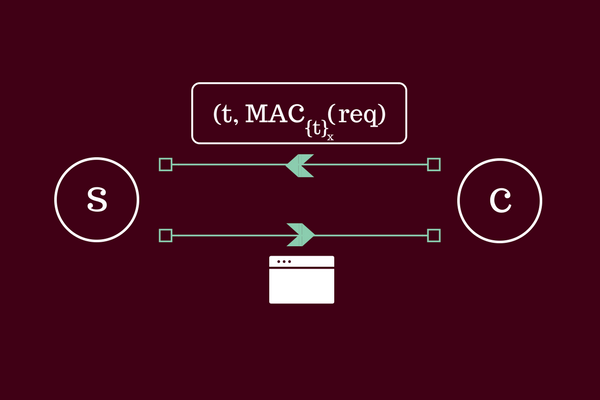
Redemption phase
- C calculates request binding data
reqand chooses an unspent token(t,N) - C calculates a shared key
sk = H_2(t,N)and sends(t, MAC_sk(req))to S - S recalculates
req'based on the request data that it witnesses - S checks that
thas not been spent already and calculatesT = H_1(t),N = xT, andsk = H_2(t,N) - Finally S checks that
MAC_sk(req') =?= MAC_sk(req), and storestto check against future redemptions
If all the steps above pass, then the server validates that the user has a validly signed token. When we refer to ‘passes’ we mean the pair (t, MAC_sk(req)) and if verification is successful the edge server grants the user access to the requested resource.
Cryptographic security of protocol
There are many different ways in which we need to ensure that the protocol remains “secure”. Clearly one of the main features is that the user remains anonymous in the transaction. Furthermore, we need to show that the client is unable to leverage the protocol in order to learn the private key of the edge, or arbitrarily gain infinite tokens. We give two security arguments for our protocol that we can easily reduce to cryptographic assumptions on the hardness of widely-used problems. There are a number of other security goals for the protocol but we consider the two arguments below as fundamental security requirements.
Unlinkability in the presence of an adversarial edge
Similarly to the RSA blind signing protocol, the blind r is used to prevent the edge from learning the value of T, above. Since r is not used in the redemption phase of the protocol, there is no way that the server can link a blinded token rT in the signing phase to any token in a given redemption phase. Since S recalculates T during redemption, it may be tempting to think that S could recover r from rT. However, the hardness of the discrete log problem prevents S from launching this attack. Therefore, the server has no knowledge of r.
As mentioned and similarly to the JKK14 OPRF protocol above, we rely on the hardness of standard cryptographic assumptions such as the discrete log problem (DLP), and collision-resistant hash functions. Using these hardness assumptions it is possible to write a proof of security in the presence of a dishonest server. The proof of security shows that assuming that these assumptions are hard, then a dishonest server is unable to link an execution of the signing phase with any execution of the redemption phase with probability higher than just randomly guessing.
Intuitively, in the signing phase, C sends randomly distributed data due to the blinding mechanism and so S cannot learn anything from this data alone. In the redemption phase, C unveils their token, but the transcript of the signing phase witnessed by S is essentially random and so it cannot be used to learn anything from the redemption phase.
This is not a full proof of security but gives an idea as to how we can derive cryptographic hardness for the underlying protocol. We hope to publish a more detailed cryptographic proof in the near future to accompany our protocol design.
Key privacy for the edge
It is also crucial to prove that the exchange does not reveal the secret key x to the user. If this were to happen, then the user would be able to arbitrarily sign their own tokens, giving them an effectively infinite supply.
Notice that the only time when the client is exposed to the key is when they receive Z = xM. In elliptic-curve terminology, the client receives their blinded token scalar multiplied with x. Notice, that this is also identical to the interaction that an adversary witnesses in the discrete log problem. In fact, if the client was able to compute x from Z, then the client would also be able to solve the DLP — which is thought to be very hard for established key sizes. In this way, we have a sufficient guarantee that an adversarial client would not be able to learn the key from the signing interaction.
Preventing further deanonymization attacks using “Verifiable” OPRFs
While the proof of security above gives some assurances about the cryptographic design of the protocol, it does not cover the possibility of possible out-of-band deanonymization. For instance, the edge server can sign tokens with a new secret key each time. Ignoring the cost that this would incur, the server would be able to link token signing and redemption phases by simply checking the validation for each private key in use.
There is a solution known as a ‘discrete log equivalence proof’ (DLEQ proof). Using this, a server commits to a secret key x by publicly posting a pair (G, xG) for a generator G of the prime-order group G. A DLEQ proof intuitively allows the server to prove to the user that the signed tokens Z = xrT and commitment xG both have the same discrete log relation x. Since the commitment is posted publicly (similarly to a Certificate Transparency Log) this would be verifiable by all users and so the deanonymization attack above would not be possible.
DLEQ proofs
The DLEQ proof objects take the form of a Chaum-Pedersen CP93 non-interactive zero-knowledge (NIZK) proof. Similar proofs were used in JKK14 to show that their OPRF protocol produced “verifiable” randomness, they defined their construction as a VOPRF. In the following, we will describe how these proofs can be augmented into the signing phase above.
The DLEQ proof verification in the extension is still in development and is not completely consistent with the protocol below. We hope to complete the verification functionality in the near future.
Let M = rT be the blinded token that C sends to S, let (G,Y) = (G,xG) be the commitment from above, and let H_3 be a new hash function (modelled as a random oracle for security purposes). In the protocol below, we can think of S playing the role of the ‘prover’ and C the ‘verifier’ in a traditional NIZK proof system.
- S computes
Z = xM, as before. - S also samples a random nonce
k ← ZZ_qand commits to the nonce by calculatingA = kGandB = kM - S constructs a challenge
c ← H_3(G,Y,M,Z,A,B)and computess = k-cx (mod q) - S sends
(c,s)to the user C - C recalculates
A' = sG + cYandB' = s*M + c*Zand hashesc' = H_3(G,Y,M,Z,A’,B’). - C verifies that
c' =?= c.
Note that correctness follows since
A' = sG + cY = (k-cx)G + cxG = kG and B' = sM + cZ = r(k-cx)T + crxT = krT = kM
We write DLEQ(Z/M == Y/G) to denote the proof that is created by S and validated by C.
In summary, if both parties have a consistent view of (G,Y) for the same epoch then the proof should verify correctly. As long as the discrete log problem remains hard to solve, then this proof remains zero-knowledge (in the random oracle model). For our use-case the proof verifies that the same key x is used for each invocation of the protocol, as long as (G,Y) does not change.
Batching the proofs
Unfortunately, a drawback of the proof above is that it has to be instantiated for each individual token sent in the protocol. Since we send 30 tokens by default, this would require the server to also send 30 DLEQ proofs (with two EC elements each) and the client to verify each proof individually.
Interestingly, Henry showed that it was possible to batch the above NIZK proofs into one object with only one verification required Hen14. Using this batching technique substantially reduces the communication and computation cost of including the proof.
Let n be the number of tokens to be signed in the interaction, so we have M_i = r_i*T_i for the set of blinded tokens corresponding to inputs t_i.
- S generates corresponding
Z_i = x*M_i - S also computes a seed
z = H_3(G,Y,M_1,...,M_n,Z_1,...,Z_n) - S then initializes a pseudorandom number generator PRNG with the seed
zand outputsc_1, ... , c_n ← PRNG(z)where the output domain of PRNG isZZ_q - S generates composite group elements:
M = (c_1*M_1) + ... + (c_n*M_n), Z = (c_1*Z_1) + ... + (c_n*Z_n)
- S calculates
(c,s) ← DLEQ(M:Z == G:Y)and sends(c,s)to C, whereDLEQ(Z/M == Y/G)refers to the proof protocol used in the non-batching case. - C computes
c’_1, … , c’_n ← PRNG(z)and re-computesM’,Z’and checks thatc’ =?= c
To see why this works, consider the reduced case where m = 2:
Z_1 = x(M_1),
Z_2 = x(M_2),
(c_1*Z_1) = c_1(x*M_1) = x(c_1*M_1),
(c_2*Z_2) = c_2(x*M_2) = x(c_2*M_2),
(c_1*Z_1) + (c_2*Z_2) = x[(c_1*M_1) + (c_2*M_2)]
Therefore, all the elliptic curve points will have the same discrete log relation as each other, and hence equal to the secret key that is committed to by the edge.
Benefits of V-OPRF vs blind RSA
While the blind RSA specification that we released fulfilled our needs, we make the following concrete gains
- Simpler, faster primitives
- 10x savings in pass size (~256 bits using P-256 instead of ~2048)
- The only thing edge to manage is a private scalar. No certificates.
- No need for public-key encryption at all, since the derived shared key used to calculate each MAC is never transmitted and cannot be found from passive observation without knowledge of the edge key or the user’s blinding factor.
- Exponentiations are more efficient due to use of elliptic curves.
- Easier key rotation. Instead of managing certificates pinned in TBB and submitted to CT, we can use the DLEQ proofs to allow users to positively verify they’re in the same anonymity set with regard to the edge secret key as everyone else.
Download
Privacy Pass v1.0 is available as a browser extension for Chrome and Firefox. If you find any issues while using then let us know.
Source code
The code for the browser extension and server has been open-sourced and can be found at https://github.com/privacypass/challenge-bypass-extension and https://github.com/privacypass/challenge-bypass-server respectively. We are welcoming contributions if you happen to notice any improvements that can be made to either component. If you would like to get in contact with the Privacy Pass team then find us at our website.
Protocol details
More information about the protocol can be found here.
Acknowledgements
The creation of Privacy Pass has been a joint effort by the team made up of George Tankersley, Ian Goldberg, Nick Sullivan, Filippo Valsorda and myself.
I’d also like to thank Eric Tsai for creating the logo and extension design, Dan Boneh for helping us develop key parts of the protocol, as well as Peter Wu and Blake Loring for their helpful code reviews. We would also like to acknowledge Sharon Goldberg, Christopher Wood, Peter Eckersley, Brian Warner, Zaki Manian, Tony Arcieri, Prateek Mittal, Zhuotao Liu, Isis Lovecruft, Henry de Valence, Mike Perry, Trevor Perrin, Zi Lin, Justin Paine, Marek Majkowski, Eoin Brady, Aaran McGuire, and many others who were involved in one way or another and whose efforts are appreciated.
References
Cha82: Chaum. Blind signatures for untraceable payments. CRYPTO’82
CP93: Chaum, Pedersen. Wallet Databases with Observers. CRYPTO’92.
Hen14: Ryan Henry. Efficient Zero-Knowledge Proofs and Applications, August 2014.
JKK14: Jarecki, Kiayias, Krawczyk. Round-Optimal Password-Protected Secret Sharing and T-PAKE in the Password-Only model.
JKKX16: Jarecki, Kiayias, Krawczyk, Xu. Highly-Efficient and Composable Password-Protected Secret Sharing.

No comments yet.