How to secure Generative AI applications
I remember when the first iPhone was announced in 2007. This was NOT an iPhone as we think of one today. It had warts. A lot of warts. It couldn’t do MMS for example. But I remember the possibility it brought to mind. No product before had seemed like anything more than a product. The iPhone, or more the potential that the iPhone hinted at, had an actual impact on me. It changed my thinking about what could be.
In the years since no other product came close to matching that level of awe and wonder. That changed in March of this year. The release of GPT-4 had the same impact I remember from the iPhone launch. It’s still early, but it's opened the imagination, and fears, of millions of developers in a way I haven’t seen since that iPhone announcement.
That excitement has led to an explosion of development and hundreds of new tools broadly grouped into a category we call generative AI. Generative AI systems create content mimicking a particular style. New images that look like Banksy or lyrics that sound like Taylor Swift. All of these Generative AI tools, whether built on top of GPT-4 or something else, use the same basic model technique: a transformer.
Attention is all you need
GPT-4 (Generative Pretrained Transformer) is the most advanced version of a transformer model. Transformer models all emerged from a seminal paper written in 2017 by researchers at the University of Toronto and the team at Google Brain, titled Attention is all you need. The key insight from the paper is the self-attention mechanism. This mechanism replaced recurrent and convolutional layers, allowing for faster training and better performance.
The secret power of transformer models is their ability to efficiently process large amounts of data in parallel. It's the transformers' gargantuan scale and extensive training that makes them so appealing and versatile, turning them into the Swiss Army knife of natural language processing. At a high level, Large Language Models (LLMs) are just transformer models that use an incredibly large number of parameters (billions), and are trained on incredibly large amounts of unsupervised text (the Internet). Hence large, and language.
Groundbreaking technology brings groundbreaking challenges
Unleashing the potential of LLMs in consumer-facing AI tools has opened a world of possibilities. But possibility also means new risk: developers must now navigate the unique security challenges that arise from making powerful new tools widely available to the masses.
First and foremost, consumer-facing applications inherently expose the underlying AI systems to millions of users, vastly increasing the potential attack surface. Since developers are targeting a consumer audience, they can't rely on trusted customers or limit access based on geographic location. Any security measure that makes it too difficult for consumers to use defeats the purpose of the application. Consequently, developers must strike a delicate balance between security and usability, which can be challenging.
The current popularity of AI tools makes explosive takeoff more likely than in the past. This is great! Explosive takeoff is what you want! But, that explosion can also lead to exponential growth in costs, as the computational requirements for serving a rapidly growing user base can become overwhelming.
In addition to being popular, Generative AI apps are unique in that calls to them are incredibly resource intensive, and therefore expensive for the owner. In comparison, think about a more traditional API that Cloudflare has protected for years. A product API. Sites don’t want competitors calling their product API and scraping data. This has an obvious negative business impact. However, it doesn’t have a direct infrastructure cost. A product list API returns a small amount of text. An attacker calling it 4 million times will have a negligible cost to an infrastructure bill. But generative models can cost cents, or in the case of image generation even tens of cents per call. An attacker gaining access and generating millions of calls has a real cost impact to the developers providing those APIs.
Not only are the costs for generating content high, but the value that end users are willing to pay is high as well. Customers tell us that they have seen multiple instances of bad actors accessing an API without paying, then reselling the content they generate for 50 cents or more per call. The huge monetary opportunity of exploitation means attackers are highly motivated to come back again and again, refactoring their approach each time.
Last, consumer-facing LLM applications are generally designed as a single entry point for customers, almost always accepting query text as input. The open-text nature of these calls makes it difficult to predict the potential impact of a single request. For example, a complex query might consume significant resources or trigger unexpected behavior. While these APIs are not GraphQL based, the challenges are similar. When you accept unstructured submissions, it's harder to create any type of rule to prevent abuse.
Tips for protecting your Generative AI application
So you've built the latest generative AI sensation, and the world is about to be taken by storm. But that success is also about to make you a target. What's the trick to stopping all those attacks you’re about to see? Well, unfortunately there isn’t one. For all the reasons above, this is a hard, persistent problem with no simple solution. But, we’ve been fortunate to work with many customers who have had that target on their back for months, and we’ve learned a lot from that experience. Here are some recommendations that will give you a good foundation for making sure that you, and only you, reap the rewards of your hard work.
1. Enforce tokens for each user. Enforcing usage based on a specific user or user session is straightforward. But sometimes you want to allow anonymous usage. While anonymous usage is great for demos and testing, it can lead to abuse. If you must allow anonymous usage, create a “stickier” identification scheme that persists browser restarts and incognito mode. Your goal isn’t to track specific users, but instead to understand how much an anonymous user has already used your service so far in demo / free mode.
2. Manage quotas carefully. Your service likely incurs costs and charges users per API call, so it likely makes sense to set a limit on the number of times any user can call your API. You may not ever intend for the average user to hit this limit, but having limits in place will protect against that user’s API key becoming compromised and shared amongst many users. It also protects against programming errors that could result in 100x or 1000x expected usage, and a large unexpected bill to the end user.
3. Block certain ASNs (autonomous system numbers) wholesale. Blocking ASNs, or even IPs wholesale is an incredibly blunt tool. In general Cloudflare rarely recommends this approach to customers. However, when tools are as popular as some generative AI applications, attackers are highly motivated to send as much traffic as possible to those applications. The fastest and cheapest way to accomplish this is through data centers that usually share a common ASN. Some ASNs belong to ISPs, and source traffic from people browsing the Internet. But other ASNs belong to cloud compute providers, and mainly source outbound traffic from virtual servers. Traffic from these servers can be overwhelmingly malicious. For example, several of our customers have found ASNs where 88-90% of the traffic turns out to be automated, while this number is usually only 30% for average traffic. In cases this extreme, blocking entire ASNs can make sense.
4. Implement smart rate limits. Counting not only requests per minute and requests per session, but also IPs per token and tokens per IP can guard against abuse. Tracking how many different IPs are using a particular token at any one time can alert you to a user's token being leaked. Similarly, if one IP is rotating through tokens, looking at each token’s session traffic would not alert you to the abuse. You’d need to look at how many tokens that single IP is generating in order to pinpoint that specific abusive behavior.
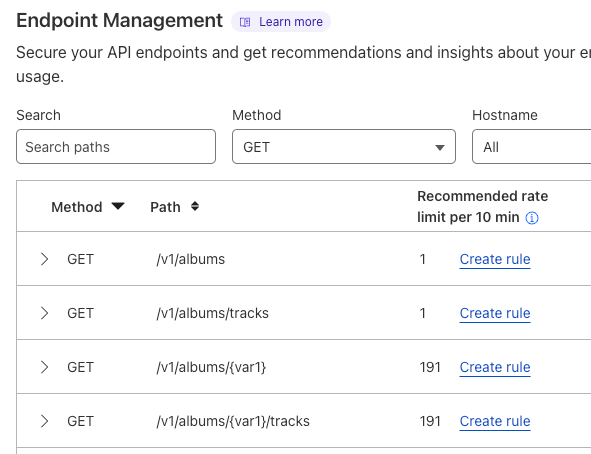
5. Rate limit on something other than the user. Similar to enforcing tokens on each user, your real time rate limits should also be set on your sticky identifier.
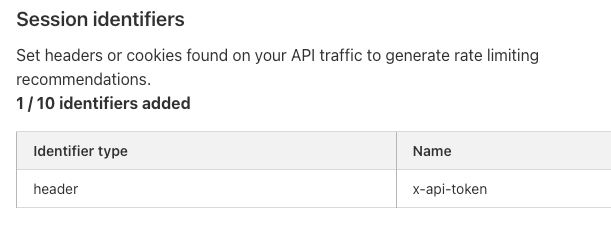
6. Have an option to slow down attackers. Customers often think about stopping abuse in terms of blocking traffic from abusers. But blocking isn’t the only option. Attacks not only need to be successful, they also need to be economically feasible. If you can make requests more difficult or time-consuming for abusers, you can ruin their economics. You can do this by implementing a waiting room, or by challenging users. We recommend a challenge option that doesn’t give real users an awful experience. Challenging users can also be quickly enabled or disabled as you see abuse spike or recede.
7. Map and analyze sequences. By sampling user sessions that you suspect of abuse, you can inspect their requests path-by-path in your SIEM. Are they using your app as expected? Or are they circumventing intended usage? You might benefit from enforcing a user flow between endpoints.
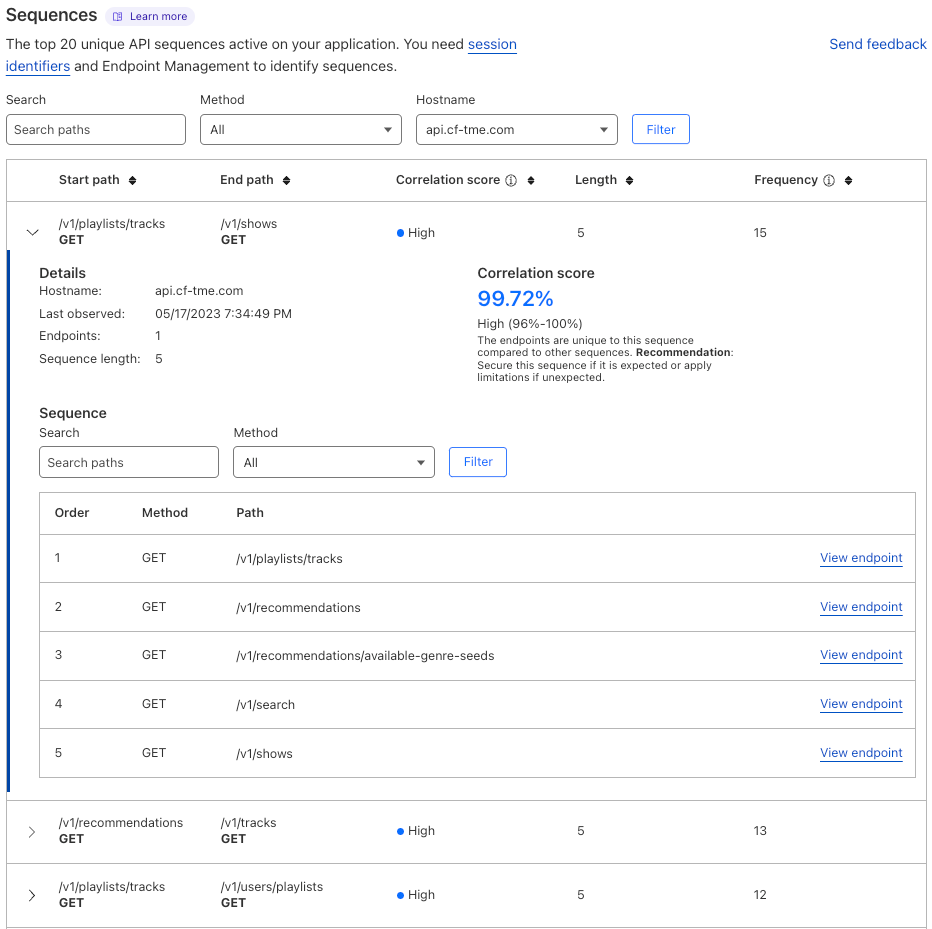
8. Build and validate an API schema. Many API breaches happen due to permissive schemas. Users are allowed to send in extra fields in requests that grant them too many privileges or allow access to other users’ data. Make sure you build a verbose schema that outlines what intended usage is by identifying and cataloging all API endpoints, then making sure all specific parameters are listed as required and have type limits to them.
We recently went through the transition to an OpenAPI schema ourselves for api.cloudflare.com. You can read more about how we did it here. Our schema looks like this:
/zones:
get:
description: List, search, sort, and filter your zones.
operationId: zone-list-zones
responses:
4xx:
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/components-schemas-response_collection'
- $ref: '#/components/schemas/api-response-common-failure'
description: List Zones response failure
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/components-schemas-response_collection'
description: List Zones response
security:
- api_email: []
api_key: []
summary: List Zones
tags:
- Zone
x-cfPermissionsRequired:
enum:
- '#zone:read'
x-cfPlanAvailability:
business: true
enterprise: true
free: true
pro: true
9. Analyze the depth and complexity of queries. Are your APIs driven by GraphQL? GraphQL queries can be a source of abuse since they allow such free-form requests. Large, complex queries can grow to overwhelm origins if limits aren’t in place. Limits help guard against outright DoS attacks as well as developer error, keeping your origin healthy and serving requests to your users as expected.
For example, if you have statistics about your GraphQL queries by depth and query size, you could execute this TypeScript function to analyze them by quantile:
import * as ss from 'simple-statistics';
function calculateQuantiles(data: number[], quantiles: number[]): {[key: number]: string} {
let result: {[key: number]: string} = {};
for (let q of quantiles) {
// Calculate quantile, convert to fixed-point notation with 2 decimal places
result[q] = ss.quantile(data, q).toFixed(2);
}
return result;
}
// Example usage:
let queryDepths = [2, 2, 2, 2, 2, 2, 2, 4, 4, 4, 4, 4, 1, 1, 1, 1, 1, 1, 1, 1];
let querySizes = [11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2];
console.log(calculateQuantiles(queryDepths, [0.5, 0.75, 0.95, 0.99]));
console.log(calculateQuantiles(querySizes, [0.5, 0.75, 0.95, 0.99]));
The results give you a sense for the depth of the average query hitting your endpoint, grouped by quantile:
{ '0.5': 2, '0.75': 3, '0.95': 4, '0.99': 4 }
{ '0.5': 6.5, '0.75': 2, '0.95': 2, '0.99': 2 }
Actual data from your production environment would provide a threshold to start an investigation into which queries to further log or limit. A simpler option is to use a query analysis tool, like Cloudflare’s, to make the process automatic.
10. Use short-lived access tokens and long-lived refresh tokens upon successful authentication of your users. Implement token validation in a middleware layer or API Gateway, and be sure to have a dedicated token renewal endpoint in your API. JSON Web Tokens (JWTs) are popular choices for these short-lived tokens. When access tokens expire, allow users to obtain new ones using their refresh tokens. Revoke refresh tokens when necessary to maintain system security. Adopting this approach enhances your API's security and user experience by effectively managing access and mitigating the risks associated with compromised tokens.
11. Communicate directly with your users. All of the above recommendations are going to make it a bit more cumbersome for some of your customers to use your product. You are going to get complaints. You can reduce these by first, giving clear communication to your users explaining why you put these measures in place. Write a blog about what security measures you did and did not decide to implement and have dev docs explaining troubleshooting steps to resolve. Second, give your users concrete steps they can take if they are having trouble, and a clear way to contact you directly. Feeling inconvenienced can be frustrating, but feeling stuck can lose you a customer.
Conclusion: this is the beginning
Generative AI, like the first iPhone, has sparked a surge of excitement and innovation. But that excitement also brings risk, and innovation brings new security holes and attack vectors. The broadness and uniqueness of generative AI applications in particular make securing them particularly challenging. But as every scout knows, being prepared ahead of time means less stress and worry during the journey. Implementing the tips we've shared can establish a solid foundation that will let you sit back and enjoy the thrill of building something special, rather than worrying what might be lurking around the corner.
To learn more about how you can put some of these recommendations into practice, check out our developer platform, API Security, and Rate Limiting products.
