2023年10月4日の1.1.1.1ルックアップ障害

2023年10月4日、Cloudflareで07:00~11:00 (協定世界時) にかけてDNS解決に関する障害が発生しました。一部の1.1.1.1の利用者、または1.1.1.1を使用するWarp 、Zero Trust、サードパーティDNSリゾルバなどの製品の一部の利用者が、有効なクエリに対して「SERVFAIL DNS」応答を受信した可能性があります。この度は、ご迷惑をおかけして大変申し訳ございませんでした。この障害は内部的なソフトウェアのエラーであり、攻撃によるものではありません。このブログでは、障害の経緯、発生理由、そして再発防止に対する当社の取り組みについて説明します。
背景
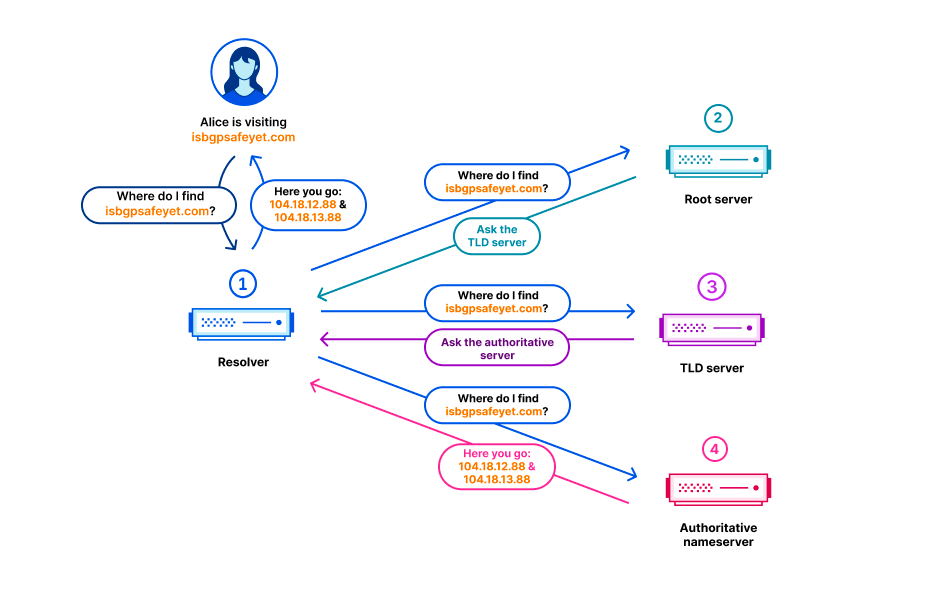
ドメインネームシステム(DNS)の仕組みでは、すべてのドメイン名はDNSゾーン内に存在します。ゾーンには、ドメイン名とホスト名のセットの集合体が管理されています。たとえば、Cloudflareはcloudflare.comというドメイン名を管理しており、これは「cloudflare.com」ゾーンにあると言えます。トップレベルドメイン(TLD)「.com」はサードパーティが所有し、「com」ゾーンにあります。comによってcloudflare.comへのアクセス方法が示されます。すべてのTLDの上位には各TLDへのアクセス方法を示す、ルートゾーンがあります。そのため、ルートゾーンは他のすべてのドメイン名を解決できるようにするために重要な存在です。DNSの他の重要な部分と同様に、ルートゾーンもDNSSECで署名されており、ルートゾーン自体には暗号署名が含まれています。
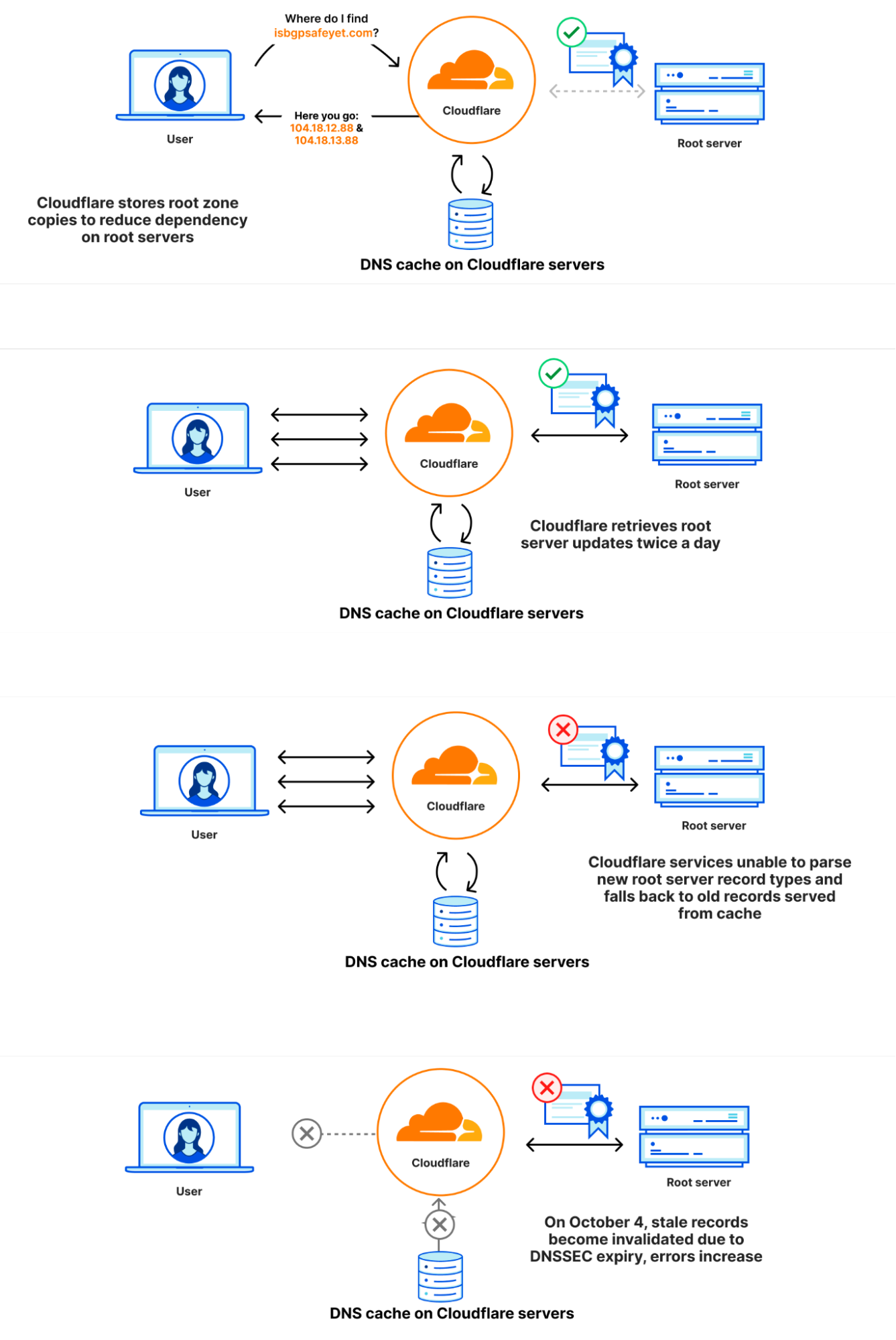
ルートゾーンはルートサーバーによって公開されていますが、多くのDNS運用者は一般的にルートサーバーに到達できない場合でもルートゾーンの情報を利用できるようにルートゾーンのコピーを自動的に取得して保持するようにしています。 Cloudflareの再帰DNSインフラストラクチャも解決プロセスを高速化するため、このアプローチを採用しています。ルートゾーンの新バージョンは通常1日2回公開されます。1.1.1.1では、 static_zoneと呼ばれるWebAssemblyアプリがメインのDNSロジックの上で動作しており、新バージョンが公開された段階で新バージョンを提供できるようにしています。
障害発生の原因
9月21日、ルートゾーン管理における既知の計画済みの変更の内容に、ルートゾーンに初めて、チェックサムとして機能する新たなリソースレコードタイプ「ZONEMD」が追加されるというものがありました。
ルートゾーンの情報は、Cloudflareのコアネットワークで動作するソフトウェアによって取得されます。その後、世界中のCloudflareのデータセンターに再配布されます。変更後も、ZONEMDレコードを含むルートゾーンは通常通り取得および配布は継続して実行されていました。しかし、そのデータを利用する1.1.1.1のリゾルバシステムに問題があり、ZONEMDレコードを解析することができませんでした。ゾーンは全体をロードして提供する必要があるため、システムがZONEMDを解析できなかったことにより、ルートゾーンの新バージョンをCloudflareのリゾルバシステムで使用することができなくなりました。Cloudflareのリゾルバインフラストラクチャをホストしているサーバーの中には、新しいルートゾーンの情報を受信できなかった場合、リクエストの都度、DNSルートサーバーに直接問い合わせるようにフェイルオーバーするものもあります。しかし、他のサーバーは、メモリキャッシュに保存されたルートゾーンの既知の動作バージョン(変更前の9月21日に引き出されたバージョン)の利用を続けました。
2023年10月4日7時(協定世界時)、9月21日バージョンのルートゾーンのDNSSECの有効期限が切れました。Cloudflareのリゾルバシステムで利用可能な新しいバージョンが無くなり、Cloudflareの一部のリゾルバシステムがDNSSECシグネチャを検証できなくなり、その結果、エラーレスポンス(SERVFAIL)を送信するようになりました。CloudflareリゾルバのSERVFAILレスポンス生成割合が12%増加する事態となりました。以下の図は、障害の進行と、ユーザーへの影響が表面化した経緯を示しています。
インシデントのタイムラインと影響
9月21 日6:30(協定世界時):ルートゾーンからの最後の情報引き出しの成功
10月4日7:00(協定世界時):9月21日に取得したルートゾーンのDNSSEC署名が期限切れとなり、クライアントからの問い合わせに対するSERVFAIL応答が増加。
7:57:予期せぬSERVFAILに対する最初の外部報告が入り始める。
06:32:Cloudflare社内でインシデントが宣言される。
8:50:オーバーライドルールを使用して、1.1.1.1が古いルートゾーンファイルを使用した応答を提供するのを防ぐ最初の試みを実施。
10:30:1.1.1.1のルートゾーンファイルの事前読み込みを完全に停止。10:32:応答が正常に回復。
11:02:インシデントをクローズ。
この下のグラフは、影響とSERVFAILエラーで返されたDNS問い合わせのパーセンテージを時系列で表したものです:
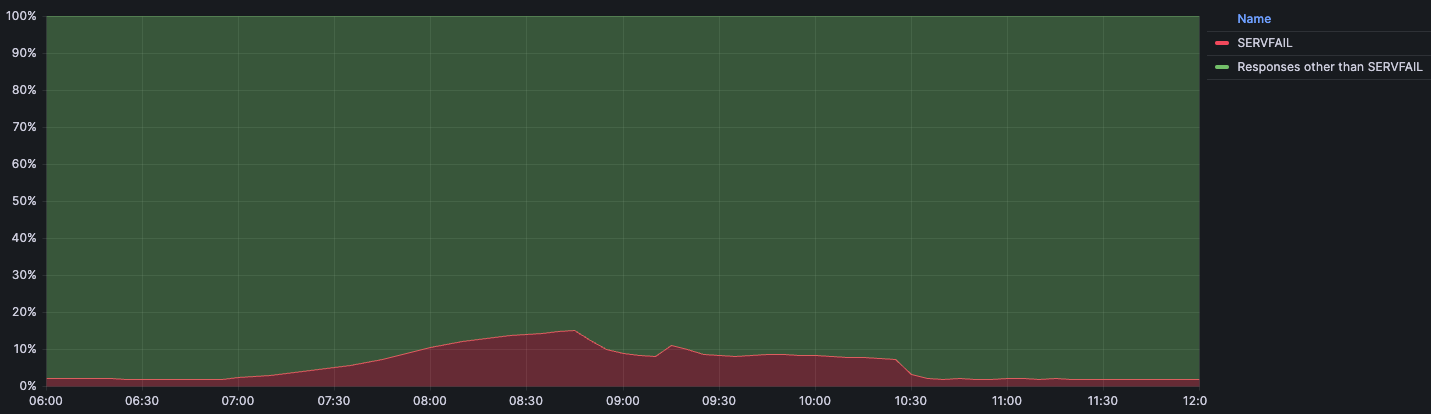
私たちは、平常時のトラフィックにおけるSERVFAILエラーの基準量(通常値)を3%程度と想定しています。この場合のSERVFAILは、DNSSECチェーンにおける正当な問題、権威サーバーへの接続の失敗、権威サーバーの応答のタイムアウト、その他多くの要因によって引き起こされる可能性があります。インシデントの間、SERVFAILの量は総クエリの15%でピークに達しましたが、その影響は世界中に均等に分散されたわけではなく、アッシュバーン(バージニア州)、フランクフルト(ドイツ)、シンガポールのような大規模なデータセンターに主に集中しました。
インシデント発生の理由
ZONEMDレコードの解析に失敗した理由
DNSは、リソースレコードの格納にバイナリ形式を採用しています。このバイナリ形式では、リソースレコードのタイプ(TYPE)は16ビットの整数として格納されます。リソースレコードのタイプが、リソースデータ(RDATA)の解析方法を決定します。レコードタイプ「1」はAレコードであることを意味し、RDATAはIPv4アドレスとして解析されます。レコードタイプ「28」はAAAAレコードを意味し、RDATAはIPv6アドレスとして解析されます。解析が未知のリソースタイプに遭遇した場合、RDATAの解析方法を判断することができないが、RDLENGTHフィールドがRDATAフィールドの長さを示すため、解析はそれを不明なデータ要素として扱うことができます。
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ /
/ NAME /
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| CLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TTL |
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| RDLENGTH |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--|
/ RDATA /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
static_zoneが新しいZONEMDレコードをサポートしなかった理由は、これまで私たちがルートゾーンをバイナリ形式ではなく、プレゼンテーション形式で内部配布することを選んできたためです。リソースレコードのテキスト表現をいくつか見てみると、異なるレコードの表示形式には、さらに多くのバリエーションがあることがわかります。
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2023100400 1800 900 604800 86400
. 86400 IN RRSIG SOA 8 0 86400 20231017050000 20231004040000 46780 . J5lVTygIkJHDBt6HHm1QLx7S0EItynbBijgNlcKs/W8FIkPBfCQmw5BsUTZAPVxKj7r2iNLRddwRcM/1sL49jV9Jtctn8OLLc9wtouBmg3LH94M0utW86dKSGEKtzGzWbi5hjVBlkroB8XVQxBphAUqGxNDxdE6AIAvh/eSSb3uSQrarxLnKWvHIHm5PORIOftkIRZ2kcA7Qtou9NqPCSE8fOM5EdXxussKChGthmN5AR5S2EruXIGGRd1vvEYBrRPv55BAWKKRERkaXhgAp7VikYzXesiRLdqVlTQd+fwy2tm/MTw+v3Un48wXPg1lRPlQXmQsuBwqg74Ts5r8w8w==
. 518400 IN NS a.root-servers.net.
. 86400 IN ZONEMD 2023100400 1 241 E375B158DAEE6141E1F784FDB66620CC4412EDE47C8892B975C90C6A102E97443678CCA4115E27195B468E33ABD9F78C
未知のリソースレコードに遭遇した際の処理方法の判断は必ずしも単純なものではありません。このため、私たちがエッジで使用するルートゾーン解析用のライブラリは、解析を行わずに代わりに解析エラーを返します。
ルートゾーンの古いバージョンが使用された理由
static_zoneアプリは、ルートゾーンをローカルに提供(FC 7706)する目的で、ルートゾーンの読み込みと解析を行い、最新バージョンをメモリに保存します。新バージョンが公開されると、static_zoneアプリがそれを解析し、解析に成功すると旧バージョンを削除します。しかし、static_zoneアプリは解析に失敗し、新しいバージョンに切り替えることができないため、古いバージョンを延々と使用し続けることになりました。1.1.1.1サービスが最初に起動されたとき、static_zoneアプリは既存のバージョンをメモリ内に持ち合わせていません。ルートゾーンを解析しようとすると失敗するものの、ルートゾーンの古いバージョンも持ち合わせていないため、ルートサーバーに直接リクエストを問い合わせることになります。
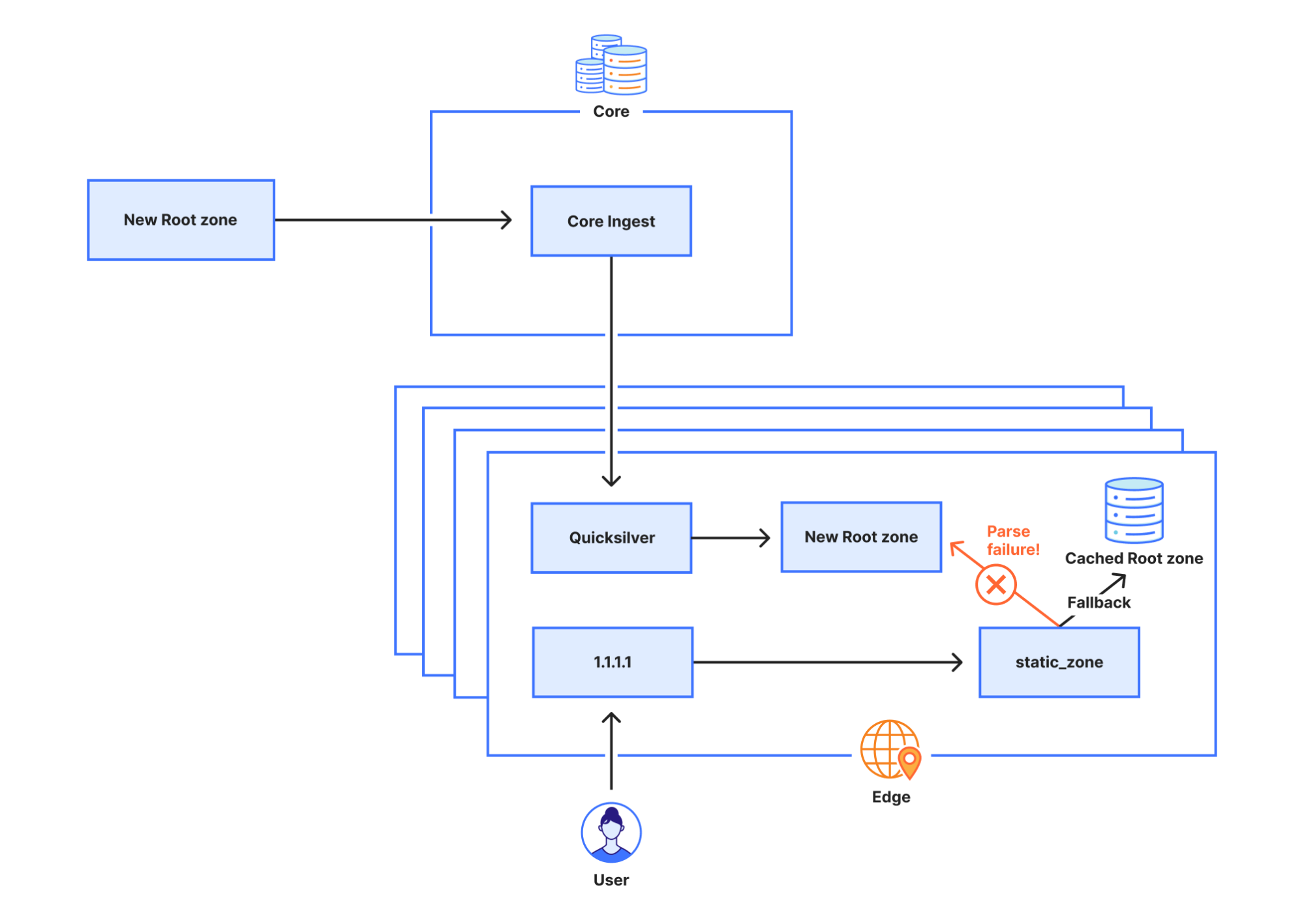
static_zoneを無効にする最初の試みがうまくいかなかった理由
当初、1.1.1.1の動作をプログラム的に変更可能な仕組みであるオーバーライドルールによってstatic_zoneアプリの無効化が試行されました。私たちが展開したルールは以下のとおりです:
phase = pre-cache set-tag rec_disable_static
このルールは、受信したリクエストに「rec_disable_static」タグを付加します。static_zoneアプリの内部でこのタグをチェックし、設定されている場合、キャッシュされた静的ルートゾーンから応答を返しません。ただし、現在のノードが自身のキャッシュから応答を見つけられない場合、キャッシュパフォーマンス向上のために、問い合わせが別のノードに転送されることがあります。残念ながら、他のノードに転送される問い合わせにはrec_disable_staticタグが含まれないため、最終的にアプリを完全に無効にするまで、static_zoneアプリは古い情報を返し続けることとなりました。
影響が部分的だった理由
Cloudflareでは、カーネルアップデートなどのシステムを完全に再起動することで有効になるタスクのため、当社のサービスをホストするサーバーを定期的に順次の再起動を実施しています。今回の障害発生時、ZONEMDの変更とDNSSECの無効化の間に再起動されたリゾルバサーバインスタンスは、影響に寄与していません。もしこの2週間の間に再起動されていた場合、起動時にルートゾーンのロードに失敗し、代わりにルートサーバーにDNSクエリを送信して解決を試みることになったでしょう。加えて、リゾルバはserve-stale(RFC 8767)と呼ばれる技法を用い、影響を抑制する目的で、アクセス数の多いレコードを、最新ではない可能性のあるキャッシュから提供し続けることになります。レコードが上流から取得されてからTTL秒数が経過すると、そのレコードは最新ではないとみなされます。これにより、完全な停止を防ぎました。影響は主に、その時間枠内に1.1.1.1サービスを再起動しなかった多数サーバーを抱える最大規模のデータセンターで発生しました。
改善とフォローアップ手順
今回のインシデントは広範囲に影響を及ぼしており、当社では当社のサービスの可用性について非常に重く受け止めております。当社はいくつかの領域における改善点の特定に至りましたが、今後も再発の原因となるその他のギャップの発見に努めてまいります。
当社が直後から取り組んでいる内容は以下のとおりです。
可視性:static_zoneが古いルートゾーンファイルを提供した場合に通知するアラートを追加しました。古いルートゾーンファイルが提供された場合に長期間気づかれないという事態は防がれるべき事象でした。もし私たちがこの件をもっときちんと監視し、キャッシングが存在していれば、影響はなかったでしょう。上流で行われた変更からお客様とそのユーザーをお守りすることが私たちの目標です。
耐障害性:内部的なルートゾーンの取得と配布方法を見直します。取得および配布のパイプラインは、新しいRRTYPEをシームレスに処理し、パイプラインの短時間の中断はエンドユーザーが気付かない程度に抑える必要があります。
テスト:新しいZONEMDレコードの解析における未公表の変更に関連するテストを含め、この問題に関するテストを実施しているにもかかわらず、ルートゾーンの解析に失敗した場合のテスト内容が不十分でした。そのため、カバレッジと関連するプロセスを改善していきます。
設計:特定の期限を過ぎたルートゾーンの古いコピーを使用すべきではありません。古いルートゾーンデータも限られた時間であれば使用し続けることは確かに可能ですが、ある時点を過ぎると、許容できない運用上のリスクが生じます。RFC 8806「Running a Root Server Local to a Resolver(ルートサーバーをリゾルバに対してローカルで実行する)」に記述されているように、キャッシュされたルートゾーンデータの有効期間をより適切に管理するための対策を講じます。
まとめ
このようなインシデントを起こしてしまったことを深くお詫び申し上げます。このインシデントから学ぶべき教訓は「変更はないだろう」と思い込まないことです。現代のシステムの多くは、最終的な実行ファイルに組み込まれる長いライブラリ群の連鎖で構築されており、そのひとつひとつにバグがあったり、変更があっても更新に遅延が発生してプログラムが正しく動作しないなどと言った事象が発生することがあります。私たちは、変更によるリグレッションを適切に検出する優れたテストや、変更に対して正常に失敗するシステムやコンポーネントを用意することがいかに重要であるかを理解しています。私たちは、インターネットの最も重要なシステム(DNSやBGP)における「形式」の変更が影響を及ぼすことを常に想定する必要があることを理解しています。
社内でフォローアップすべきことはたくさんあり、私たちは現在、このようなことを二度と起こさないよう24時間体制で取り組んでいます。
