Start auditing and controlling the AI models accessing your content
Site owners have lacked the ability to determine how AI services use their content for training or other purposes. Today, Cloudflare is releasing a set of tools to make it easy for site owners, creators, and publishers to take back control over how their content is made available to AI-related bots and crawlers. All Cloudflare customers can now audit and control how AI models access the content on their site.
This launch starts with a detailed analytics view of the AI services that crawl your site and the specific content they access. Customers can review activity by AI provider, by type of bot, and which sections of their site are most popular. This data is available to every site on Cloudflare and does not require any configuration.
We expect that this new level of visibility will prompt teams to make a decision about their exposure to AI crawlers. To help give them time to make that decision, Cloudflare now provides a one-click option in our dashboard to immediately block any AI crawlers from accessing any site. Teams can then use this “pause” to decide if they want to allow specific AI providers or types of bots to proceed. Once that decision is made, those administrators can use new filters in the Cloudflare dashboard to enforce those policies in just a couple of clicks.
Some customers have already made decisions to negotiate deals directly with AI companies. Many of those contracts include terms about the frequency of scanning and the type of content that can be accessed. We want those publishers to have the tools to measure the implementation of these deals. As part of today’s announcement, Cloudflare customers can now generate a report with a single click that can be used to audit the activity allowed in these arrangements.
We also think that sites of any size should be able to determine how they want to be compensated for the usage of their content by AI models. Today’s announcement previews a new Cloudflare monetization feature which will give site owners the tools to set prices, control access, and capture value for the scanning of their content.
What is the problem?
Until recently, bots and scrapers on the Internet mostly fell into two clean categories: good and bad. Good bots, like search engine crawlers, helped audiences discover your site and drove traffic to you. Bad bots tried to take down your site, jump the queue ahead of your customers, or scrape competitive data. We built the Cloudflare Bot Management platform to give you the ability to distinguish between those two broad categories and to allow or block them.
The rise of AI Large Language Models (LLMs) and other generative tools created a murkier third category. Unlike malicious bots, the crawlers associated with these platforms are not actively trying to knock your site offline or to get in the way of your customers. They are not trying to steal sensitive data; they just want to scan what is already public on your site.
However, unlike helpful bots, these AI-related crawlers do not necessarily drive traffic to your site. AI Data Scraper bots scan the content on your site to train new LLMs. Your material is then put into a kind of blender, mixed up with other content, and used to answer questions from users without attribution or the need for users to visit your site. Another type of crawler, AI Search Crawler bots, scan your content and attempt to cite it when responding to a user’s search. The downside is that those users might just stay inside of that interface, rather than visit your site, because an answer is assembled on the page in front of them.
This murkiness leaves site owners with a hard decision to make. The value exchange is unclear. And site owners are at a disadvantage while they play catch up. Many sites allowed these AI crawlers to scan their content because these crawlers, for the most part, looked like “good” bots — only for the result to mean less traffic to their site as their content is repackaged in AI-written answers.
We believe this poses a risk to an open Internet. Without the ability to control scanning and realize value, site owners will be discouraged to launch or maintain Internet properties. Creators will stash more of their content behind paywalls and the largest publishers will strike direct deals. AI model providers will in turn struggle to find and access the long tail of high-quality content on smaller sites.
Both sides lack the tools to create a healthy, transparent exchange of permissions and value. Starting today, Cloudflare equips site owners with the services they need to begin fixing this. We have broken out a series of steps we recommend all of our customers follow to get started.
Step 1: Understand how AI models use your site
Every site on Cloudflare now has access to a new analytics view that summarizes the crawling behavior of popular and known AI services. You can begin reviewing this information to understand the AI scanning of your content by selecting a site in your dashboard and navigating to the AI Audit tab in the left-side navigation bar.
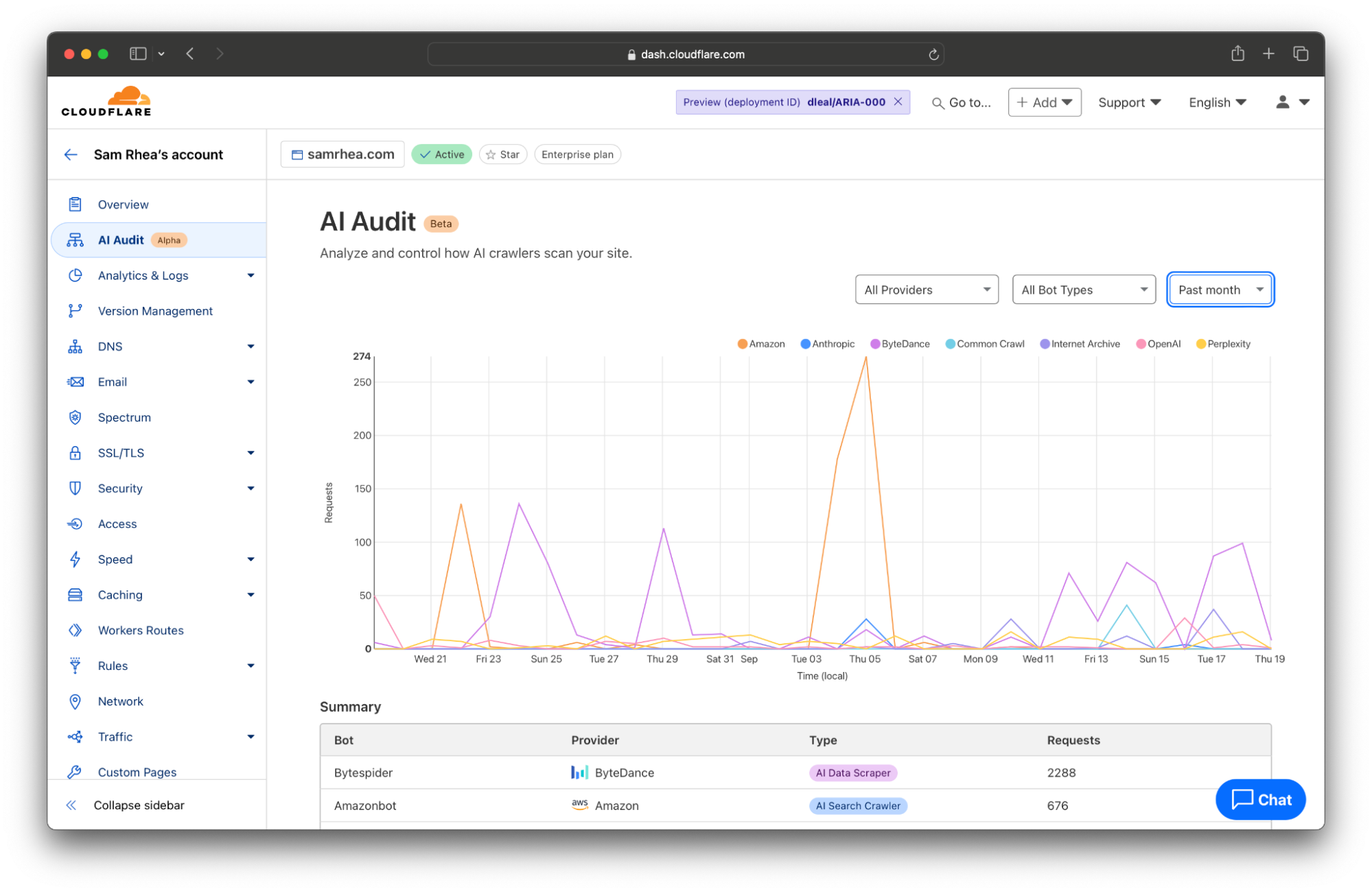
When AI model providers access content on your site, they rely on automated tools called “bots” or “crawlers” to scan pages. The bot will request the content of your page, capture the response, and store it as part of a future data training set or remember it for AI search engine results in the future.
These bots often identify themselves to your site (and Cloudflare’s network) by including an HTTP header in their request called a User Agent. Although, in some cases, a bot from one of these AI services might not send the header and Cloudflare instead relies on other heuristics like IP address or behavior to identify them.
When the bot does identify itself, the header will contain a string of text with the bot name. For example, Anthropic sometimes crawls sites on the Internet with a bot called ClaudeBot. When that service requests the content of a page from your site on Cloudflare, Cloudflare logs the User Agent as ClaudeBot.
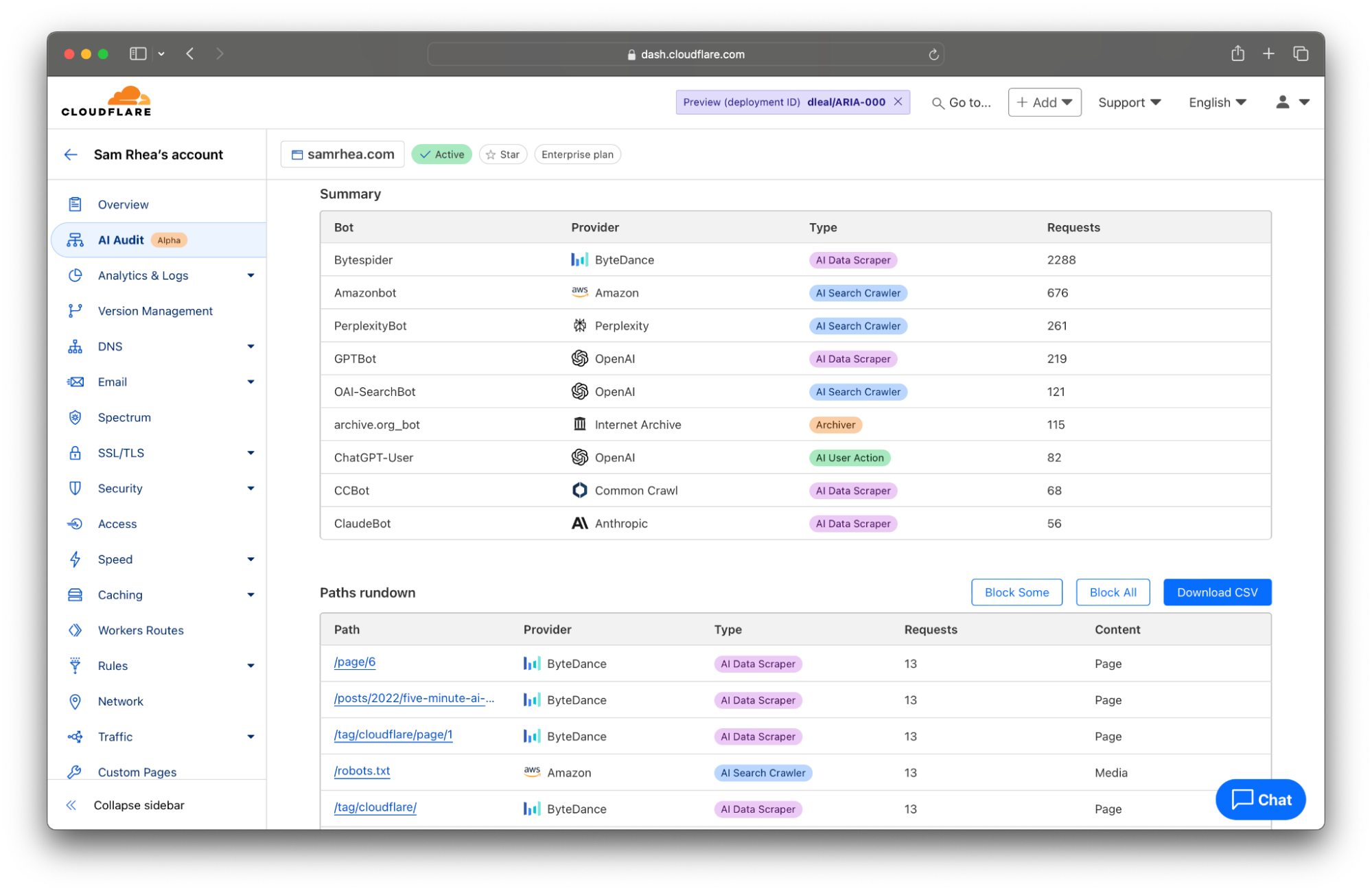
Cloudflare takes the logs gathered from visits to your site and looks for user agents that match known AI bots and crawlers. We summarize the activity of individual crawlers and also provide you with filters to review just the activities of specific AI platforms. Many AI firms rely on multiple crawlers that serve distinct purposes. When OpenAI scans sites for data scraping, they rely on GPTBot, but when they crawl sites for their new AI search engine, they use OAI-SearchBot.
And those differences matter. Scanning from different bot types can impact traffic to your site or the attribution of your content. AI search engines will often link to sites as part of their response, potentially sending visitors to your destination. In that case, you might be open to those types of bots crawling your Internet property. AI Data Scrapers, on the other hand, just exist to read as much of the Internet as possible to train future models or improve existing ones.
We think that you deserve to know why a bot is crawling your site in addition to when and how often. Today’s release gives you a filter to review bot activity by categories like AI Data Scraper, AI Search Crawler, and Archiver.
With this data, you can begin analyzing how AI models access your site. That information might be overwhelming, especially if your team has not had time yet to decide how you want to handle AI scanning of your content. If you find yourself unsure on how to respond, proceed to Step 2.
Step 2: Give yourself a pause to decide what to do next
We talked to several organizations who know their sites are valuable destinations for AI crawlers, but they do not yet know what to do about it. These teams need a “time out” so they can make an informed decision about how they make their data available to these services.
Cloudflare gives you that easy button right now. Any customer on any plan can choose to block all AI bots and crawlers to give yourself a pause while you decide what you do want to allow.
To implement that option, navigate to the Bots section under the Security tab of the Cloudflare Dashboard. Follow the blue link in the top right corner to configure how Cloudflare’s proxy handles bot traffic. Next, toggle the button in the “Block AI Scrapers and Crawlers” card to the “On” position.
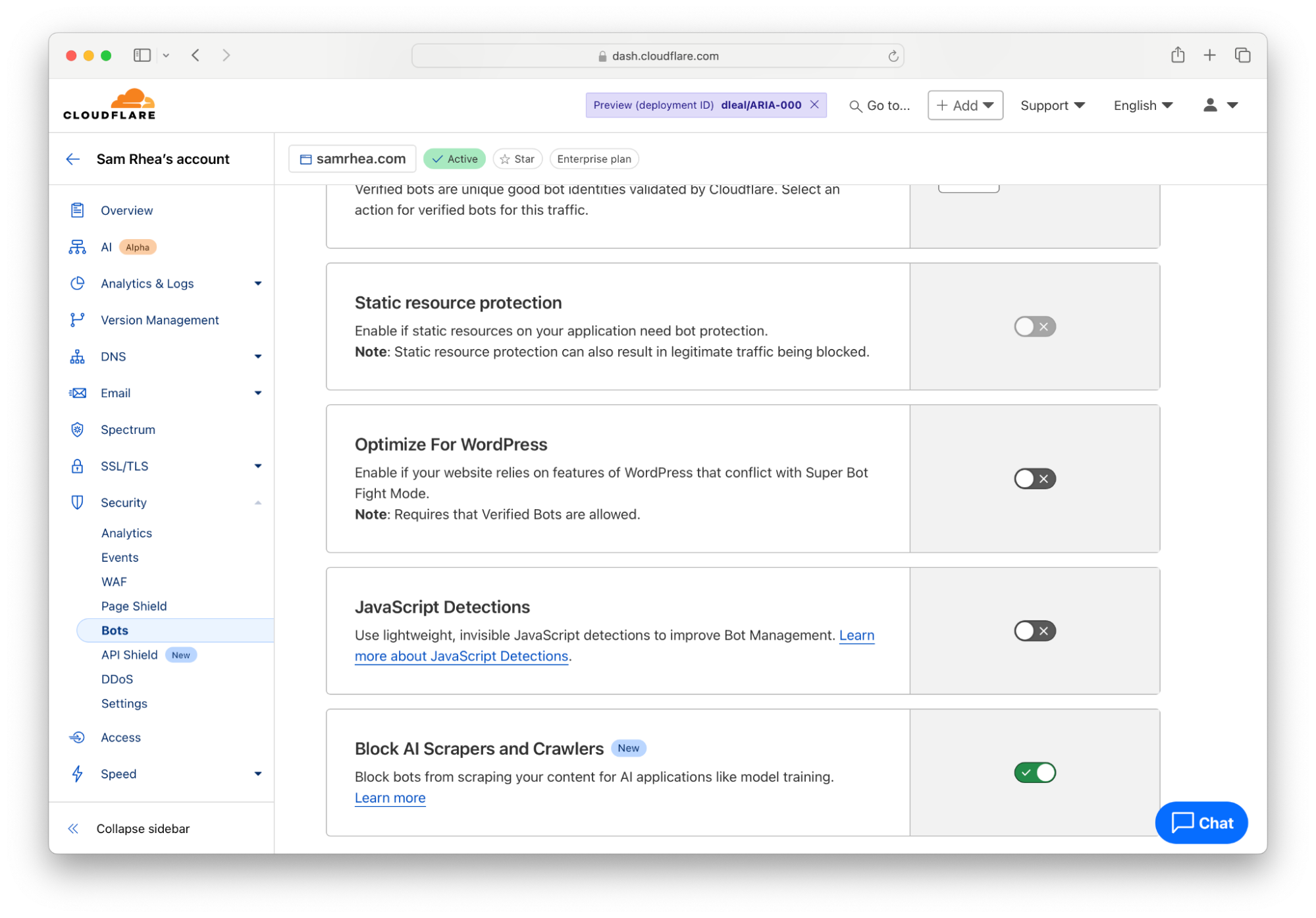
The one-click option blocks known AI-related bots and crawlers from accessing your site based on a list that Cloudflare maintains. With a block in place, you and your team can make a less rushed decision about what to do next with your content.
Step 3: Control the bots you do want to allow
The pause button buys time for your team to decide what you want the relationship to be between these crawlers and your content. Once your team has reached a decision, you can begin relying on Cloudflare’s network to implement that policy.
If that decision is “we are not going to allow any crawling,” then you can leave the block button discussed above toggled to “On”. If you want to allow some selective scanning, today’s release provides you with options to permit certain types of bots, or just bots from certain providers, to access your content.
For some teams, the decision will be to allow the bots associated with AI search engines to scan their Internet properties because those tools can still drive traffic to the site. Other organizations might sign deals with a specific model provider, and they want to allow any type of bot from that provider to access their content. Customers can now navigate to the WAF section of the Cloudflare dashboard to implement these types of policies.
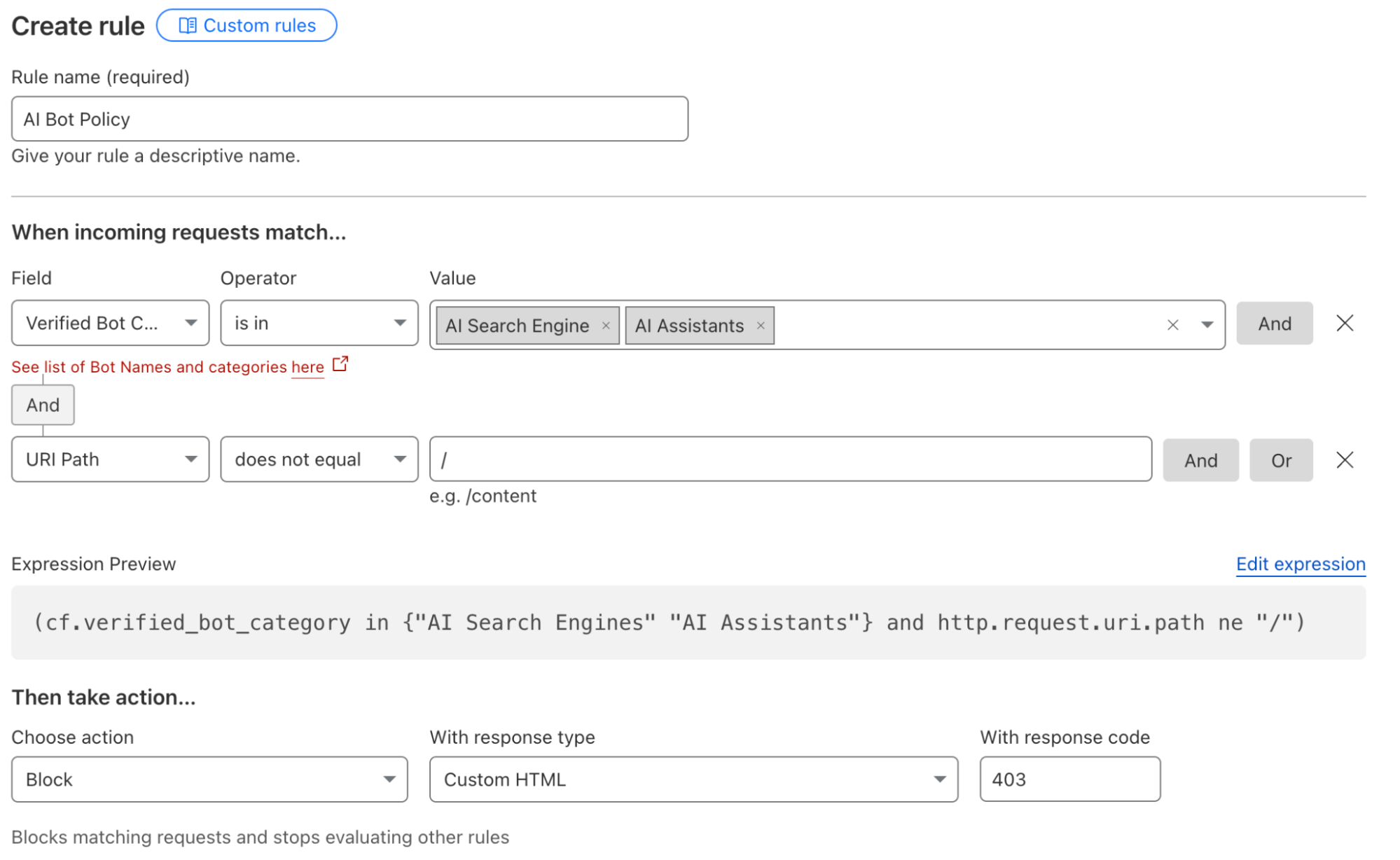
Administrators can also create rules that would, for example, block all AI bots except for those from a specific platform. Teams can deploy these types of filters if they are skeptical of most AI platforms but comfortable with one AI model provider and its policies. These types of rules can also be used to implement contracts where a site owner has negotiated to allow scanning from a single provider. The site administrator would need to create a rule to block all types of AI-related bots and then add an exception that allows the specific bot or bots from their AI partner.
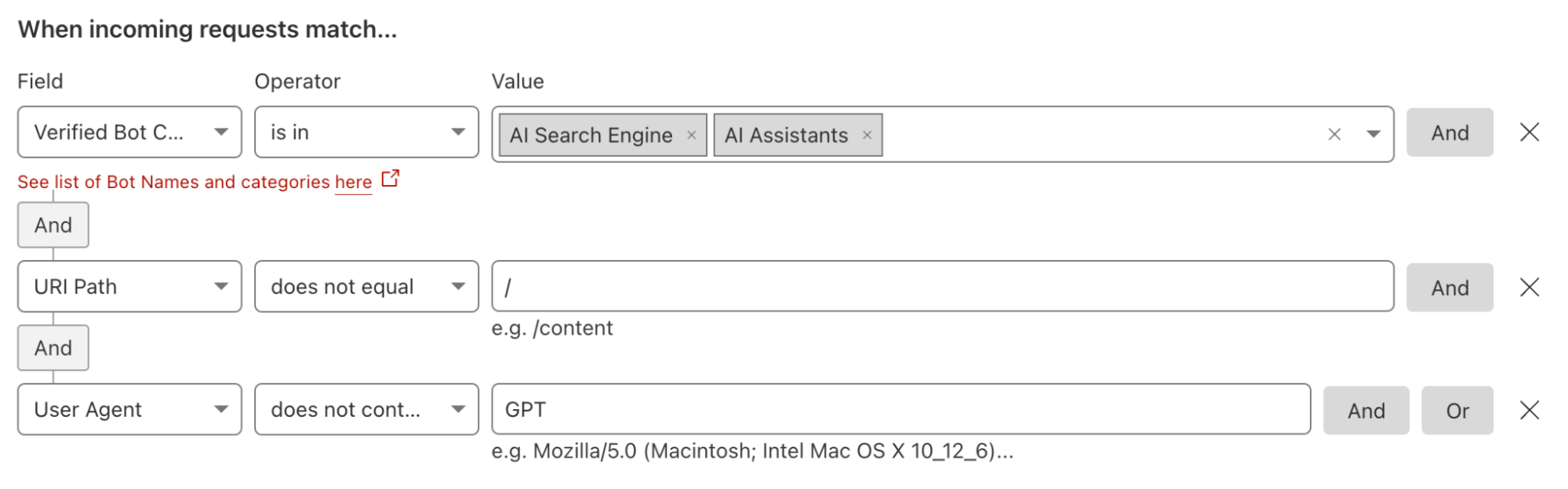
We also recommend that customers consider updating their Terms of Service to cover this new use case in addition to applying these new filters. We have documented the steps we suggest that “good citizen” bots and crawlers take with respect to robots.txt files. As an extension of those best practices, we are adding a new section to that documentation where we provide a sample Terms of Service section that site owners can consider using to establish that AI scanning needs to follow the policies you have defined in your robots.txt file.
Step 4: Audit your existing scanning arrangements
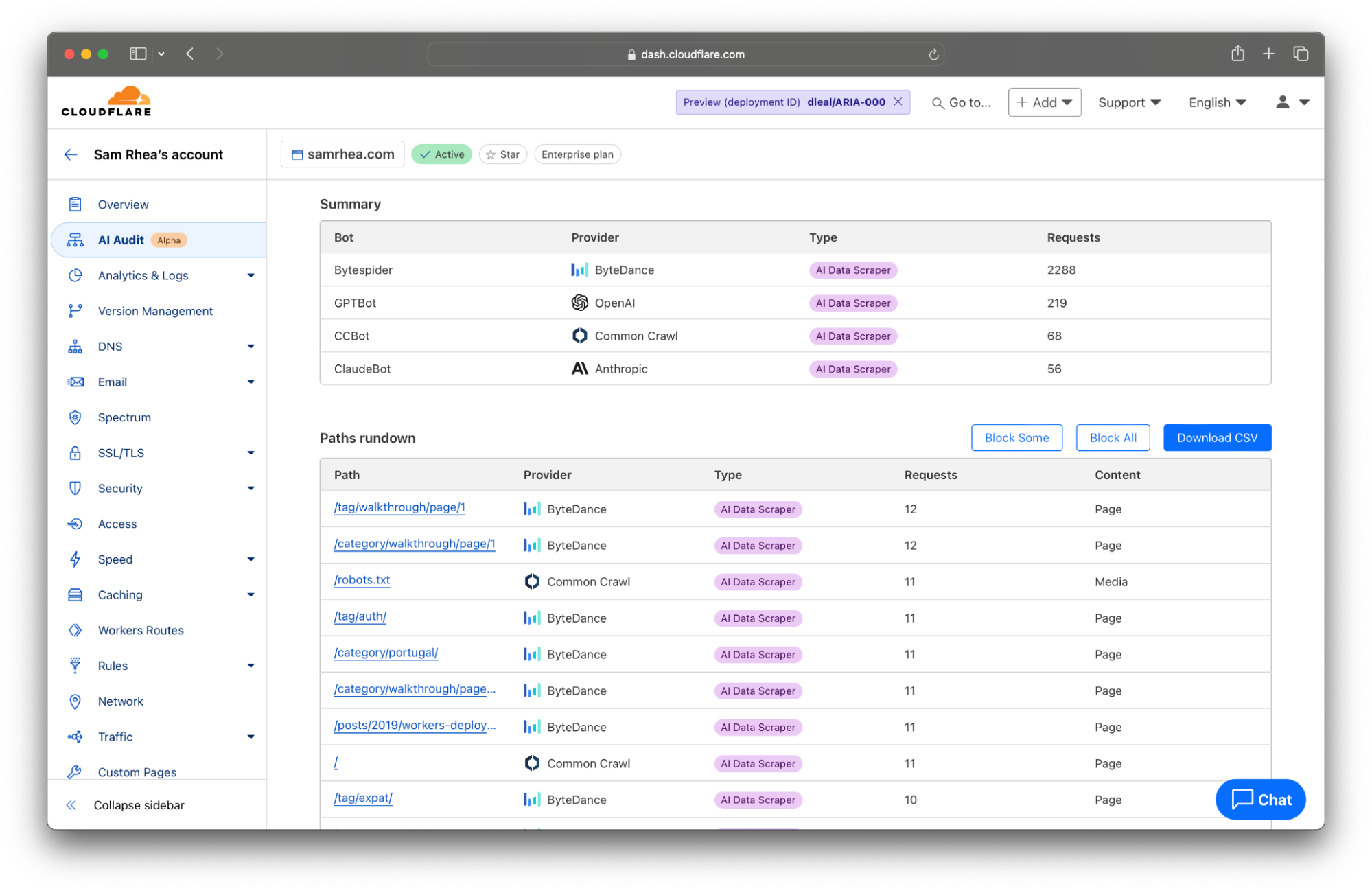
An increasing number of sites are signing agreements directly with model providers to license consumption of their content in exchange for payment. Many of those deals contain provisions that determine the rate of crawling for certain sections or entire sites. Cloudflare’s AI Audit tab provides you with the tools to monitor those kinds of contracts.
The table at the bottom of the AI Audit tool now lists the most popular content on your site ranked by the count of scans in the time period from the filter set at the top of the page. You can click the Export to CSV button to quickly download a file with the details presented here that you can use to discuss any discrepancies with the AI platform that you are allowing to access your content.
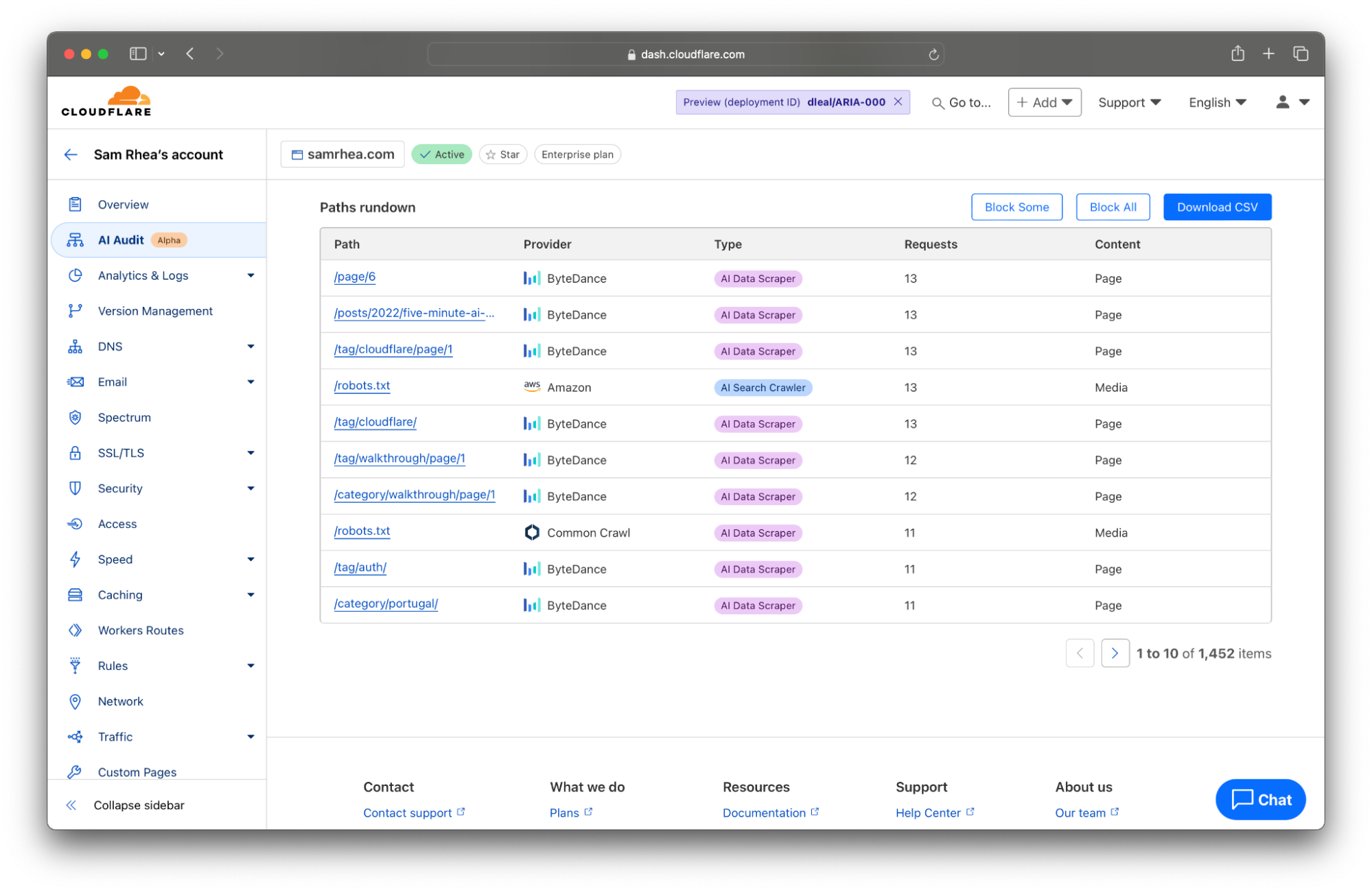
Today, the data available to you represents key metrics we have heard from customers in these kinds of arrangements: requests against certain pages and requests against the entire site.
Step 5: Prepare your site to capture value from AI scanning
Not everyone has the time or contacts to negotiate deals with AI companies. Up to this point, only the largest publishers on the Internet have the resources to set those kinds of terms and get paid for their content.
Everyone else has been left with two basic choices on how to handle their data: block all scanning or allow unrestricted access. Today’s releases give content creators more visibility and control than just those two options, but the long tail of sites on the Internet still lack a pathway to monetization.
We think that sites of any size should be fairly compensated for the use of their content. Cloudflare plans to launch a new component of our dashboard that goes beyond just blocking and analyzing crawls. Site owners will have the ability to set a price for their site, or sections of their site, and to then charge model providers based on their scans and the price you have set. We’ll handle the rest so that you can focus on creating great content for your audience.
The fastest way to get ready to capture value through this new component is to make sure your sites use Cloudflare’s network. We plan to invite sites to participate in the beta based on the date they first joined Cloudflare. Interested in being notified when this is available? Let us know here.