Fallos de la búsqueda de 1.1.1.1 del 4 de octubre de 2023

El 4 de octubre de 2023, Cloudflare sufrió problemas en la resolución de DNS entre las 07:00 y las 11:00 UTC. Algunos usuarios de 1.1.1.1 o de productos como WARP, Zero Trust o de solucionadores DNS externos que utilicen 1.1.1.1 pueden haber recibido respuestas SERVFAIL DNS a consultas válidas. Lamentamos mucho esta interrupción. Fue debido a un error interno del software y no fue consecuencia de ningún ataque. En esta publicación del blog, hablaremos acerca de en qué consistió el fallo, por qué se produjo y qué estamos haciendo para garantizar que no se repita.
Antecedentes
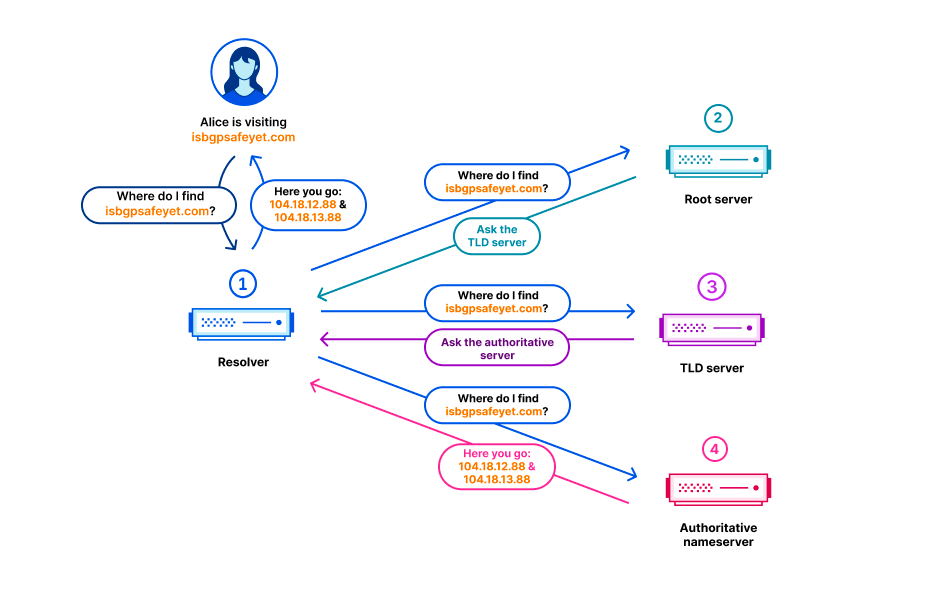
En el sistema de nombres de dominio (DNS), cada nombre de dominio existe en una zona DNS, que está formada por un conjunto de nombres de dominio y nombres de servidor que se controlan juntos. Por ejemplo, Cloudflare es responsable del nombre de dominio cloudflare.com, que decimos que está en la zona “cloudflare.com”. El dominio de nivel superior (TLD) .com es propiedad de un tercero y está en la zona “com”. Proporciona indicaciones acerca de cómo llegar a cloudflare.com. Por encima de todos los TLD se encuentra la zona raíz, que ofrece indicaciones acerca de cómo llegar a los TLD. Esto significa que la zona raíz es importante para poder resolver todos los demás nombres de dominio. Al igual que otros componentes importantes del DNS, la zona raíz está firmada con DNSSEC, lo que significa que la propia zona raíz contiene firmas criptográficas.
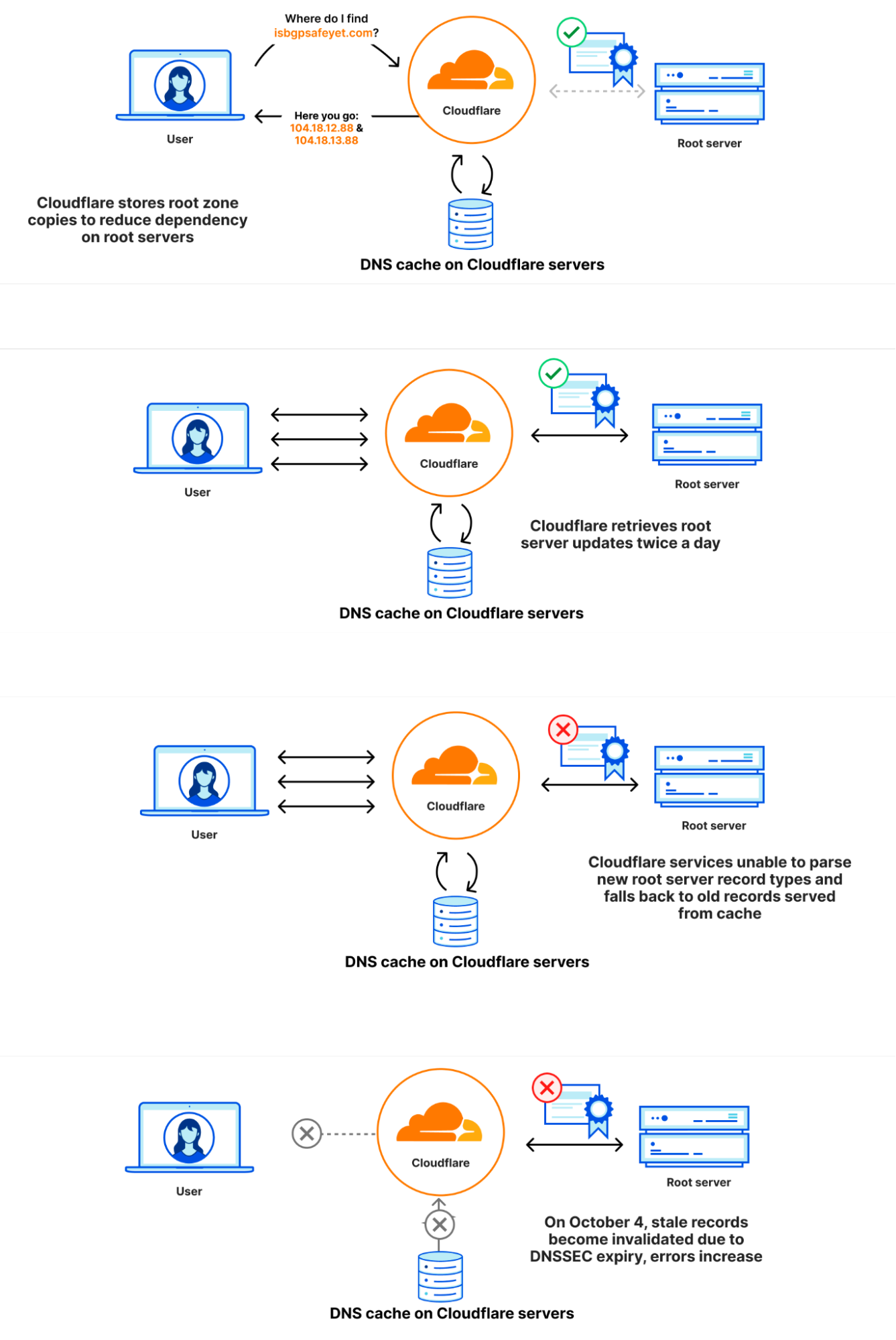
La zona raíz se publica en los servidores raíz, pero también es habitual que los operadores de DNS recuperen y conserven automáticamente una copia de la zona raíz. De esta forma, en el caso de que no se pueda contactar con los servidores raíz, la información de la zona raíz seguirá estando disponible. La infraestructura DNS recursiva de Cloudflare adopta este enfoque, ya que también acelera el proceso de resolución. Las nuevas versiones de la zona raíz suelen publicarse dos veces al día. 1.1.1.1 tiene una aplicación WebAssembly denominada static_zone que se ejecuta sobre la lógica de DNS principal que entrega estas nuevas versiones cuando están disponibles.
Qué pasó
El 21 de septiembre, como parte de un cambio conocido y planificado en la gestión de las zonas raíz, se incluyó por primera vez en ellas un nuevo registro de recurso, denominado ZONEMD, que en realidad es una suma de comprobación del contenido de la zona raíz.
La zona raíz se recupera mediante software que se ejecuta en la red principal de Cloudflare. A continuación se redistribuye a los centros de datos de Cloudflare en todo el mundo. Tras el cambio, la recuperación y distribución de la zona raíz que contenía el registro ZONEMD continuaron con normalidad. Sin embargo, los sistemas de resolución de 1.1.1.1 que utilizan estos datos tuvieron problemas al analizar el registro ZONEMD. Debido a que las zonas se deben cargar y entregar en su totalidad, el hecho de que el sistema no pudiera analizar el registro ZONEMD significó que las nuevas versiones de la zona raíz no se utilizaban en los sistemas de resolución de Cloudflare. Algunos de los servidores que alojan la infraestructura de resolución de Cloudflare, al no recibir la nueva zona raíz, pasaron a consultar los servidores raíz DNS directamente a nivel individual para cada solicitud. No obstante, otros continuaron confiando en la versión funcional conocida de la zona raíz aún disponible en su caché de memoria, que era la versión obtenida el 21 de septiembre antes del cambio.
El 4 de octubre de 2023 a las 07:00 UTC, las firmas DNSSEC en la versión de la zona raíz del 21 de septiembre caducaron. Puesto que no había ninguna versión más nueva que los sistemas de resolución de Cloudflare pudieran utilizar, algunos de ellos dejaron de poder validar las firmas DNSSEC y, como resultado, empezaron a enviar respuestas de error (SERVFAIL). La velocidad a la que los solucionadores de Cloudflare generaron respuestas SERVFAIL aumentó un 12 %. Los diagramas siguientes muestran la evolución del fallo y cómo se visualizó para los usuarios.
Cronología e impacto del incidente
21 de septiembre 6:30 UTC: última extracción correcta de la zona raíz.
4 de octubre 7:00 UTC: las firmas DNSSEC en la zona raíz obtenidas el 21 de septiembre caducan, lo que causa un incremento de las respuestas SERVFAIL a las consultas de los clientes.
7:57: se empiezan a recibir las primeras notificaciones externas acerca de respuestas SERVFAIL inesperadas.
8:03: se declara un incidente interno de Cloudflare.
8:50: se realiza un intento inicial con una regla de anulación para evitar que 1.1.1.1 entregue respuestas utilizando el archivo de zona raíz obsoleto.
10:30: se evita que 1.1.1.1 precargue el archivo de zona raíz en su totalidad.
10:32: las respuestas vuelven a la normalidad.
11:02: se cierra el incidente.
El gráfico siguiente muestra la cronología del impacto del incidente junto con el porcentaje de consultas DNS que se devolvieron con un error SERVFAIL:
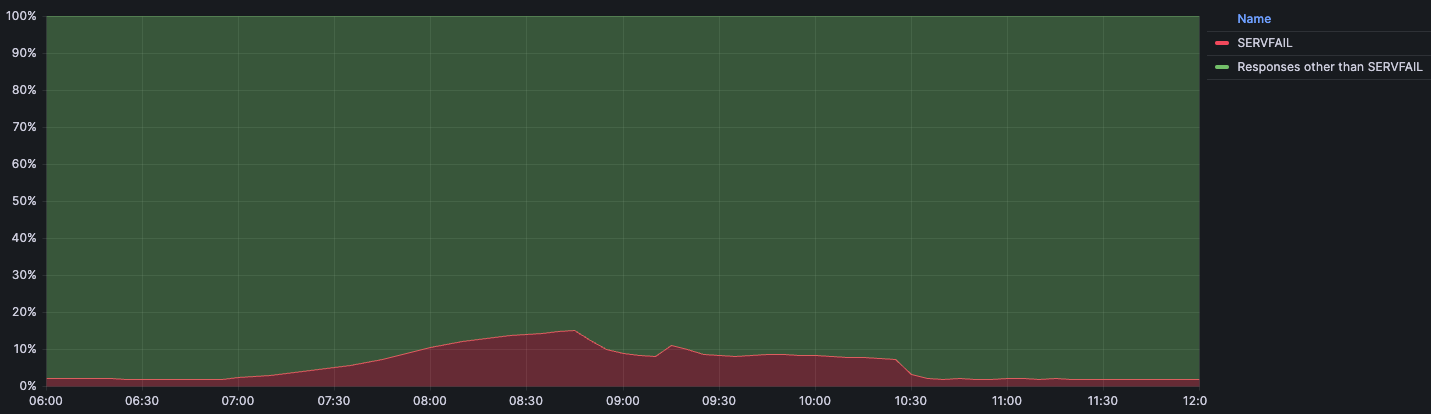
Esperamos un volumen de línea base de errores SERVFAIL para el tráfico habitual durante el funcionamiento normal. Ese porcentaje suele girar en torno al 3 %. Estos errores SERVFAIL pueden ser debidos a problemas reales en la cadena DNSSEC, a la imposibilidad de conectarse a los servidores autoritativos, a que los servidores autoritativos tardan demasiado en responder y a muchos otros motivos. Durante el incidente, el número máximo de errores SERVFAIL fue del 15 % del total de consultas, aunque la repercusión no fue uniforme en todo el mundo y se concentró principalmente en nuestros centros de datos más grandes, como los de Ashburn (Virginia), Fráncfort (Alemania) y Singapur.
Por qué se produjo este incidente
Por qué falló el análisis del registro ZONEMD
DNS tiene un formato binario para el almacenamiento de registros de recursos. En este formato binario, el tipo del registro de recurso (TYPE) se almacena como un entero de 16 bits. El tipo de registro de recurso determina cómo se analizan los datos del recurso (RDATA). Cuando el tipo de registro es 1, esto significa que es un registro A, y que RDATA se puede analizar como una dirección IPv4. En cambio, el tipo de registro 28 es un registro AAAA, cuyo RDATA se puede analizar como una dirección IPv6. Cuando un analizador se encuentra con un tipo de recurso desconocido, no sabrá cómo analizar su RDATA, pero afortunadamente no tiene que hacerlo: el campo RDLENGTH indica la longitud del campo RDATA, lo que permite al analizador tratarlo como un elemento de datos opaco.
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ /
/ NAME /
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| CLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TTL |
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| RDLENGTH |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--|
/ RDATA /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
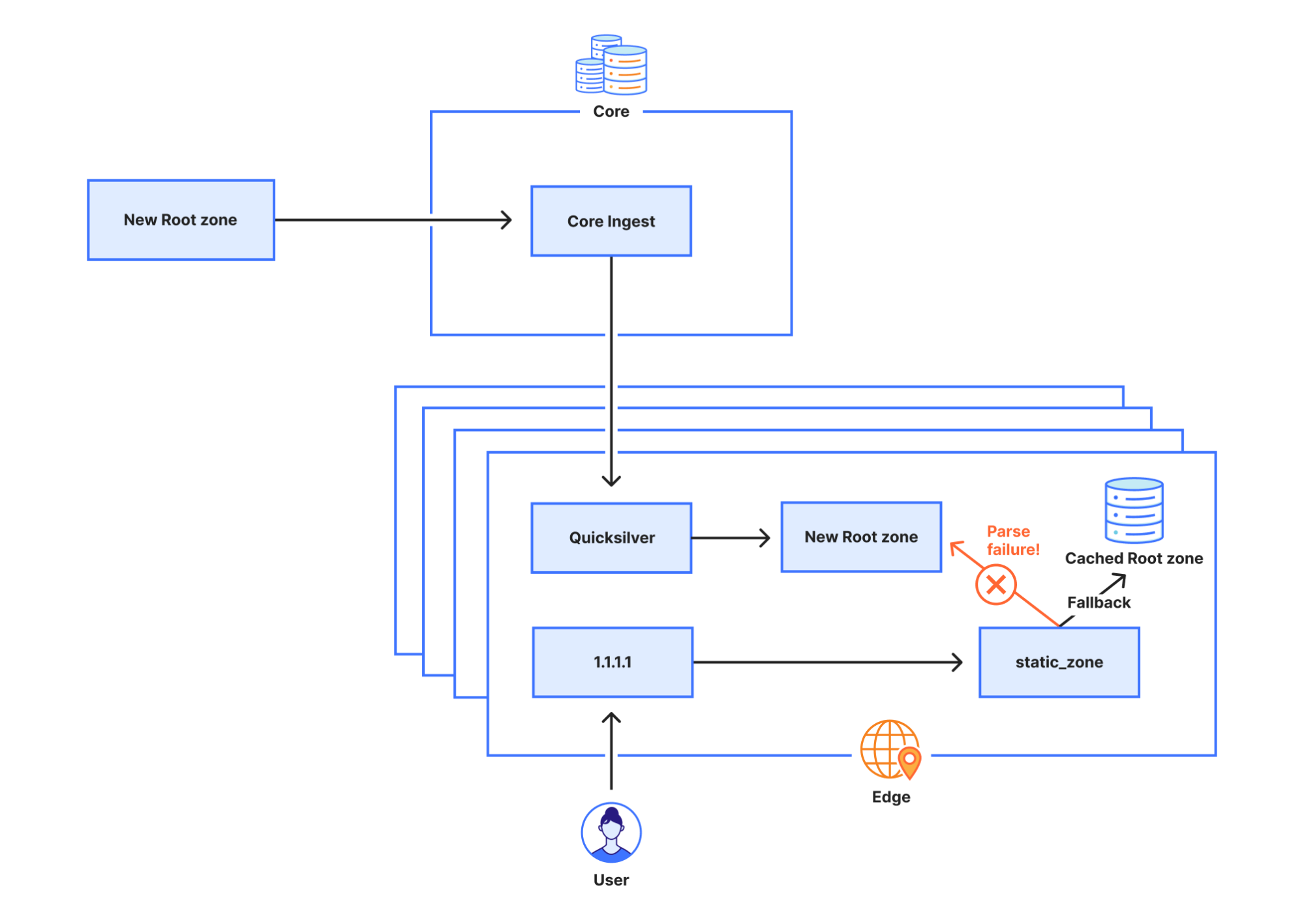
El motivo por el que static_zone no admitió el nuevo registro ZONEMD es porque hasta ahora habíamos optado por distribuir la zona raíz internamente en su formato de presentación, en lugar de en formato binario. Si miramos la representación de texto de algunos registros de recursos, podemos ver que hay mucha variación en cómo se presentan los distintos recursos.
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2023100400 1800 900 604800 86400
. 86400 IN RRSIG SOA 8 0 86400 20231017050000 20231004040000 46780 . J5lVTygIkJHDBt6HHm1QLx7S0EItynbBijgNlcKs/W8FIkPBfCQmw5BsUTZAPVxKj7r2iNLRddwRcM/1sL49jV9Jtctn8OLLc9wtouBmg3LH94M0utW86dKSGEKtzGzWbi5hjVBlkroB8XVQxBphAUqGxNDxdE6AIAvh/eSSb3uSQrarxLnKWvHIHm5PORIOftkIRZ2kcA7Qtou9NqPCSE8fOM5EdXxussKChGthmN5AR5S2EruXIGGRd1vvEYBrRPv55BAWKKRERkaXhgAp7VikYzXesiRLdqVlTQd+fwy2tm/MTw+v3Un48wXPg1lRPlQXmQsuBwqg74Ts5r8w8w==
. 518400 IN NS a.root-servers.net.
. 86400 IN ZONEMD 2023100400 1 241 E375B158DAEE6141E1F784FDB66620CC4412EDE47C8892B975C90C6A102E97443678CCA4115E27195B468E33ABD9F78C
Cuando nos encontramos con un registro de recurso desconocido, no siempre es fácil saber cómo gestionarlo. Por este motivo, la biblioteca que utilizamos para analizar la zona raíz en el perímetro no intenta hacer esto, y en su lugar devuelve un error del analizador.
Por qué se utilizó una versión obsoleta de la zona raíz
La aplicación static_zone, cuya tarea es cargar y analizar la zona raíz con la finalidad de entregar la zona raíz a nivel local (RFC 7706), almacena la última versión en memoria. Cuando se publica una nueva versión la analiza y, cuando ha completado correctamente el análisis, descarta la versión anterior. Sin embargo, puesto que el análisis falló, la aplicación static_zone nunca cambió a la nueva versión, y continuó utilizando la versión anterior indefinidamente. Cuando el servicio 1.1.1.1 se inicia por primera vez, la aplicación static_zone no tiene ninguna versión existente en memoria. Cuando intenta analizar la zona raíz, el análisis falla, pero puesto que no tiene ninguna versión anterior de la zona raíz de reserva, recurre a consultar los servidores raíz directamente para las solicitudes entrantes.
Por qué el intento inicial de desactivar static_zone no funcionó
En un principio, intentamos desactivar la aplicación static_zone mediante reglas de anulación, un mecanismo que nos permite modificar mediante programación determinados comportamientos de 1.1.1.1. La regla que implementamos fue la siguiente:
phase = pre-cache set-tag rec_disable_static
Para toda solicitud entrante, esta regla añade la etiqueta rec_disable_static a la solicitud. En la aplicación static_zone, buscamos esta etiqueta y, si está establecida, no devolvemos una respuesta desde la zona raíz estática en caché. No obstante, a fin de mejorar el rendimiento de la caché las consultas a veces se reenvían a otro nodo en el caso de que el nodo actual no pueda encontrar la respuesta en su propia caché. Lamentablemente, la etiqueta rec_disable_static no está incluida en las consultas que se reenvían a otros nodos, por lo que la aplicación static_zone continuó respondiendo con información obsoleta hasta que finalmente desactivamos la aplicación por completo.
Por qué el impacto fue parcial
Cloudflare realiza periódicamente reinicios secuenciales de los servidores que alojan nuestros servicios a fin de realizar tareas como las actualizaciones de kernel, que requieren un reinicio completo del sistema para entrar en vigor. Cuando se produjo esta interrupción, las instancias de servidor de solucionador que se habían reiniciado entre el cambio de ZONEMD y la invalidación de DNSSEC no contribuyeron al impacto. Si se hubieran reiniciado durante este plazo de dos semanas, no habrían podido cargar la zona raíz al iniciarse y habrían recurrido para la resolución a enviar las consultas DNS a los servidores raíz. Además, el solucionador utiliza una técnica denominada serve-stale (RFC 8767) con la finalidad de poder continuar entregando registros populares desde una caché potencialmente obsoleta a fin de limitar el impacto. Se considera que un registro está obsoleto cuando ha transcurrido el número de segundos de TTL desde la recuperación del registro de los niveles superiores. Esto evitó una interrupción total; los afectados fueron principalmente nuestros centros de datos más grandes, donde había muchos servidores que no habían reiniciado el servicio 1.1.1.1 en ese periodo.
Medidas de corrección y seguimiento
Este incidente tuvo una amplia repercusión, y nos tomamos la disponibilidad del servicio muy en serio. Hemos identificado varias áreas de mejora y seguiremos trabajando para descubrir cualquier otra vulnerabilidad que pudiera causar una repetición del incidente.
Estamos trabajando de forma inmediata en lo siguiente:
Visibilidad: hemos añadido alertas que notifican cuando static_zone entrega un archivo de zona raíz obsoleto. Esta entrega de un archivo de zona raíz obsoleto que se ha producido no debería haber pasado inadvertida durante tanto tiempo. Con una mejor supervisión y con el almacenamiento en caché existente, esto no habría tenido ninguna repercusión. Nuestro objetivo global es proteger a nuestros clientes y sus usuarios de los cambios en los niveles superiores.
Resiliencia: reevaluaremos cómo absorbemos y distribuimos la zona raíz internamente. Nuestros procesos de ingesta y distribución deberían gestionar nuevos RRTYPE sin problemas, y cualquier breve interrupción del proceso debería ser invisible para los usuarios finales.
Pruebas: a pesar de realizar pruebas en torno a este problema, incluidas pruebas relacionadas con cambios aún no publicados en el análisis de los nuevos registros ZONEMD, no probamos adecuadamente lo que sucede cuando falla el análisis de la zona raíz. Mejoraremos la cobertura de nuestras pruebas y los procesos relacionados.
Arquitectura: no deberíamos utilizar copias obsoletas de la zona raíz pasado cierto punto. Aunque sin duda es posible continuar utilizando datos de la zona raíz obsoleta durante cierto tiempo, pasado cierto punto esto implica riesgos operativos inaceptables. Tomaremos medidas para garantizar una mejor gestión de la duración de los datos de zona raíz en caché, tal como se describe en RFC 8806: Running a Root Server Local to a Resolver.
Conclusión
Lamentamos mucho este incidente. Y la lección está clara: no debemos asumir nunca que algo no va a cambiar. Muchos sistemas modernos se han desarrollado con una larga cadena de bibliotecas que se añaden al ejecutable final, cada una de las cuales puede contener errores o no haberse actualizado con antelación suficiente para que los programas funcionen correctamente cuando se produzcan cambios en los datos de entrada. Comprendemos la importancia de realizar pruebas adecuadas a fin de poder detectar regresiones y los sistemas y componentes que fallan cuando hay cambios en los datos de entrada. Comprendemos que necesitamos suponer siempre que los cambios de “formato” en los sistemas más críticos de Internet (DNS y BGP) van a tener repercusiones.
Debemos realizar un exhaustivo seguimiento interno y vamos a trabajar sin descanso para garantizar que este tipo de incidente no se repita.
