How we think about Zero Trust Performance


Cloudflare has done several deep dives into Zero Trust performance in 2023 alone: one in January, one in March, and one for Speed Week. In each of them, we outline a series of tests we perform and then show that we’re the fastest. While some may think that this is a marketing stunt, it’s not: the tests we devised aren’t necessarily built to make us look the best, our network makes us look the best when we run the tests.
We’ve discussed why performance matters in our blogs before, but the short version is that poor performance is a threat vector: the last thing we want is for your users to turn off Zero Trust to get an experience that is usable for them. Our goal is to improve performance because it helps improve the security of your users, the security of the things that matter most to you, and enables your users to be more productive.
When we run Zero Trust performance tests, we start by measuring end-to-end latency from when a user sends a packet to when the Zero Trust proxy receives, forwards, and inspects the packet, to when the destination website processes the packet and all the way back to the user. This number, called HTTP Response, is often used in Application Services tests to measure the performance of CDNs. We use this to measure our Zero Trust services as well, but it’s not the only way to measure performance. Zscaler measures their performance through something called proxy latency, while Netskope measures theirs through a decrypted latency SLA. Some providers don’t think about performance at all!
There are many ways to view network performance. However, at Cloudflare we believe the best way to measure performance is to use end-to-end HTTP response measurements. In this blog, we’re going to talk about why end-to-end performance is the most important thing to look at, why other methods like proxy latency and decrypted latency SLAs are insufficient for performance evaluations, and how you can measure your Zero Trust performance like we do.
Let’s start at the very beginning
When evaluating performance for any scenario, the most important thing to consider is what exactly you’re supposed to be measuring. This may seem obvious, but oftentimes the things we’re evaluating don’t do a great job of actually measuring the impact users see. A great example of this is when users look at network speed tests: measuring bandwidth doesn’t accurately measure how fast your Internet connection is.
So we must ask ourselves a fundamental question: how do users interact with Zero Trust products? The answer is they shouldn’t: or they shouldn’t know they’re interacting with Zero Trust services. Users actually interact with websites and applications hosted somewhere on the Internet: maybe they’re interacting with a private instance of Microsoft Exchange, or maybe they’re accessing Salesforce in the cloud. In any case, the Zero Trust services that sit in between serve as a forward proxy: they receive the packets from the user, filter for security and access evaluations, and then send the packets along to their destination. If the services are doing their job correctly, users won’t notice their presence at all.
So when we look at Zero Trust services, we have to look at scenarios where transparency becomes opacity: when the Zero Trust services reveal themselves and result in high latency, or even application failures. In order to simulate these scenarios, we have to access sites users would access on a regular basis. If we simulate accessing those websites through a Zero Trust platform, we can look at what happens when Zero Trust is present in the request path.
Fortunately for us, we know exactly how to simulate user requests hitting websites. We have a lot of experience measuring performance for our Developer Platform, and for our Network Benchmarking analysis. By framing Zero Trust performance in the context of our other performance analysis initiatives, it’s easy to make performance better and ensure that all of our efforts are focused on making the most people as fast as possible. Just like our analyses of other Cloudflare products, this approach puts customers and users first and ensures they get the best performance.
Challenges of the open Internet
Zero Trust services naturally come at a disadvantage when it comes to performance: they automatically add an additional network hop between users and the services they’re trying to access. That’s because a forward proxy sits between the user and the public Internet to filter and protect traffic. This means that the Zero Trust service needs to maintain connectivity with end-user ISPs, maintain connectivity with cloud providers, and transit networks that connect services that send and receive most public Internet traffic. This is generally done through peering and interconnectivity relationships. In addition to maintaining all of that connectivity, there’s also the time it takes for the service to actually process rules and packet inspections. Given all of these challenges, performance management in this scenario is complex.
Some providers try to circumvent this by scoping performance down. This is essentially what Zscaler’s proxy latency and Netskope’s decrypted latency are: an attempt to remove parts of the network path that are difficult to control and only focus on the aspects of a request they can control. To be more specific, these latencies only focus on the time that a request spends on Zscaler’s or Netskope’s physical hardware. The upside of this is that it allows these providers to make some amount of guarantee in regards to latency. This line of thinking traditionally comes from trying to replace hardware firewalls and CASB services that may not process requests inline. Zscaler and Netskope are trying to prove that they can process rules and actions inline with a request and still be performant.
But as we showed with our blog back in January, the time spent on a machine in a Zero Trust network is only a small portion of the request time experienced by the end user. The majority of a requests’ time is spent on the wire between machines. When you look at performance, you need to look at it holistically and not at a single element, like on-box processing latency. So by scoping performance down to only looking at on-box processing latencies, you’re not actually looking at anything close to the full picture of performance. To be fast, providers need to look at every aspect of the network and how they function. So let’s talk about all the elements needed to make zero trust service performance better.
How do you get better Zero Trust performance?
A good way to think of Zero Trust performance is like driving on a highway. If you’re hungry and need to eat, you want to go to a place that’s close to the highway and fast. If a restaurant that serves burgers in one second is 15 minutes out of the way, it doesn’t matter how fast they serve the burgers: the time it takes to get to that restaurant isn’t worth the trip. A McDonald’s at a rest stop may take the same amount of time as the other restaurant, but is faster end-to-end. The restaurant you pick should be close to the highway AND serve food fast. Only looking at one of the two will impact your overall time if the other aspect is slow.
Based on this analogy, in addition to having good processing times, the best ways to improve Zero Trust performance are to be well peered on the last mile, be well peered with networks that host important applications, and have diverse paths on the Internet to steer traffic around should things go wrong. Let’s go over each of those and why they’re important.
Last mile peering
We’ve talked before about how getting closer to users is critical to increase performance, but here’s a quick summary: Having a Zero Trust provider that receives your packets physically close to you straightens the path your packets take between your device and what applications you’re trying to access. Because Zero Trust networking will always incur an additional hop, if that hop is inline with the path your requests to your website would normally take, the overhead your Zero Trust network incurs is minimal.
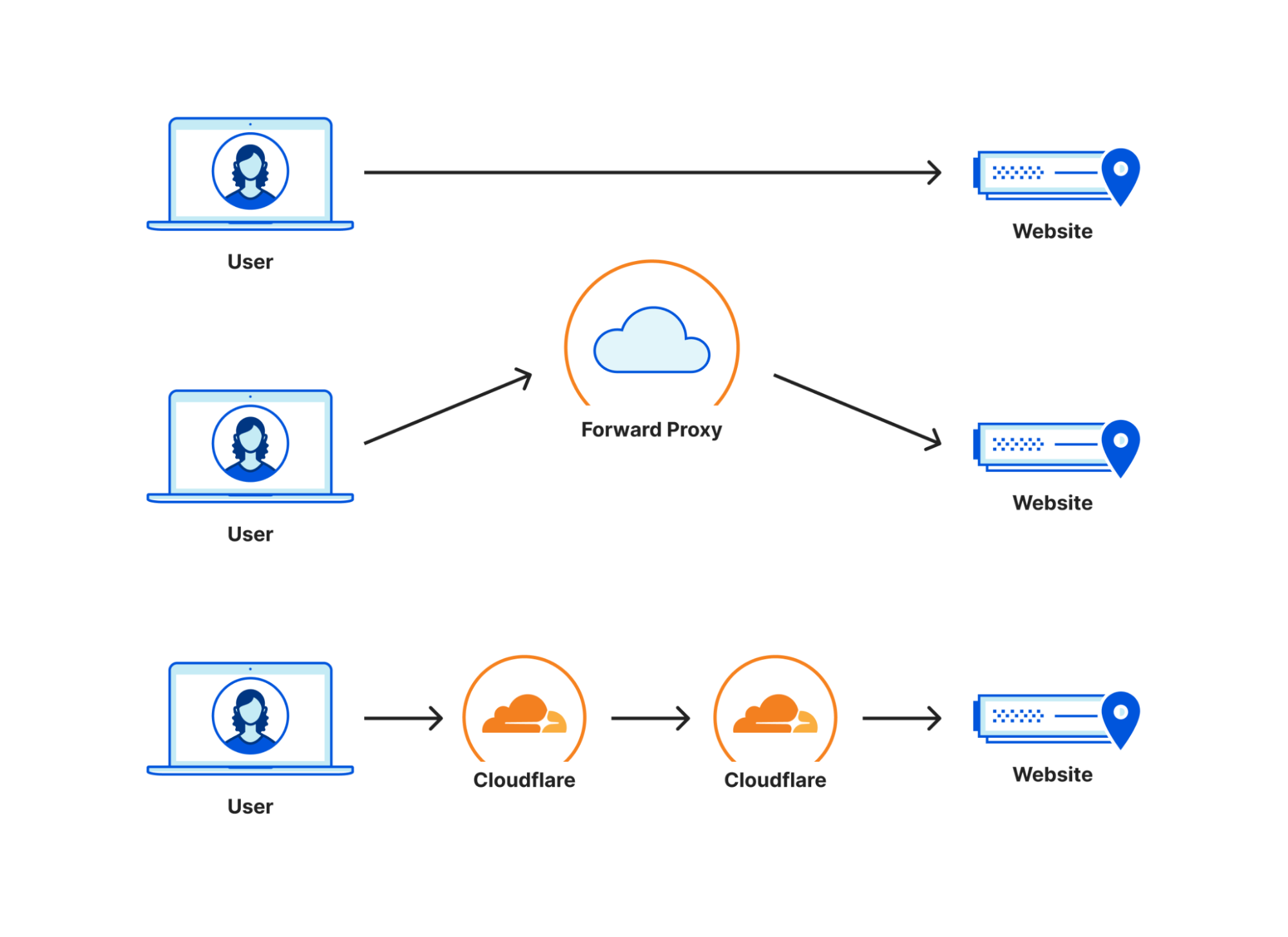
In the diagram above, you can see three connectivity models: one from a user straight to a website, one going through a generic forward proxy, and one going through Cloudflare. The length of each line is representative of the point to point latency. Based on that, you can see that the forward proxy path is longer because the two segments add up to be longer than the direct connection is. This additional travel path is referred to as a hairpin in the networking world. The goal is to keep the line between user and website as straight as possible, because that’s the shortest distance between the two.
The closer your Zero Trust provider is to you, the easier keeping the path small is to achieve. This challenge is something we’re really good at, as we’re always investing to get closer to users no matter where they are by leveraging our over 12,000 peered networks.
Cloud peering
But getting close to users is only half the battle. Once the traffic is on the Zero Trust network, it needs to be delivered to the destination. Oftentimes, those destinations are hosted in hyperscale cloud providers like Azure, Amazon Web Services, or Google Cloud. These hyperscalers are global networks with hundreds of locations for users to store data and host services. If a Zero Trust network is not well peered with all of these networks in all of the places they offer compute, that straight path starts to diverge: less than it would on the last mile, but still enough to be noticeable by end-users.
Cloudflare helps out here by being peered with these major cloud providers where they are, ensuring that the handoff between Cloudflare and the respective cloud is short and seamless. Cloudflare has peering with the major cloud providers in over 40 different metros around the world, ensuring that wherever applications may be hosted, Cloudflare is there to connect to them.
Alternative paths for everything in between
If a Zero Trust network has good connectivity on the last mile and good connectivity to the clouds, the only thing left is being able to pass traffic between the two. Having diverse network paths within the Zero Trust network is incredibly valuable for being able to shift traffic around networking issues and provide private connectivity on the Zero Trust network that is reliable and performant. Cloudflare leverages our own private backbone for this purpose, and that backbone is what helps us deliver next-level performance for all scenario types.
Getting the measurements that matter
So now that we know what scenarios we’re trying to measure and how to make them faster, how are we measuring them? The answer is elegantly simple: we make HTTP calls through our Zero Trust services and measure the Response times. When we perform our Gateway tests, we configure a client program that periodically connects to a bunch of websites commonly used by enterprises through our Zero Trust client and measure the HTTP timings to calculate HTTP response.
As we discussed before, Response is the time it takes for a user to send a packet to the Zero Trust proxy which receives, forwards, and inspects the packet, then sends it to the destination website which processes the packet and returns a response all the way back to the user. This measurement is valuable because it allows us to focus specifically on network performance and not necessarily the ability of a web application to load and render content. We don’t measure things like Largest Contentful Paint because those have dependencies on the software stack on the destination, whether the destination is fronted by a CDN and how their performance is, or even the browser making the request. We want to measure how well the Zero Trust service can deliver packets from a device to a website and back. Our current measurement methodology is focused on the time to deliver a response to the client and ignores some client side processing like browser render time (Largest Contentful Paint) and application specific metrics like UDP Video delivery.
You can do it too
Measuring performance may seem complicated, but at Cloudflare we’re trying to make it easy. Your goals of measuring user experience and our goals of providing a faster experience are perfectly aligned, and the tools we build to view performance are not only user-facing but are used internally for performance improvements. We purpose-built our Digital Experience Monitoring product to not just show where things are going wrong, but to monitor your Zero Trust performance so that you can track your user experience right alongside us. We use this data to help identify regressions and issues on our network to help ensure that you are having a good experience. With DEX, you can make tests to measure endpoints you care about just like we do in our tests, and you can see the results for HTTP Response in the Cloudflare dashboard. And the more tests you make and better visibility you get into your experience, the more you’re helping us better see Zero Trust experiences across our network and the broader Internet.
Just like everything else at Cloudflare, our performance measurements are designed with users in mind. When we measure these numbers and investigate them, we know that by making these numbers look better, we’ll improve the end-to-end experience for Zero Trust users.
