Instant Purge: invalidating cached content in under 150ms
(part 3 of the Coreless Purge series)
Over the past 14 years, Cloudflare has evolved far beyond a Content Delivery Network (CDN), expanding its offerings to include a comprehensive Zero Trust security portfolio, network security & performance services, application security & performance optimizations, and a powerful developer platform. But customers also continue to rely on Cloudflare for caching and delivering static website content. CDNs are often judged on their ability to return content to visitors as quickly as possible. However, the speed at which content is removed from a CDN’s global cache is just as crucial.
When customers frequently update content such as news, scores, or other data, it is essential they avoid serving stale, out-of-date information from cache to visitors. This can lead to a subpar experience where users might see invalid prices, or incorrect news. The goal is to remove the stale content and cache the new version of the file on the CDN, as quickly as possible. And that starts by issuing a “purge.”
In May 2022, we released the first part of the series detailing our efforts to rebuild and publicly document the steps taken to improve the system our customers use, to purge their cached content. Our goal was to increase scalability, and importantly, the speed of our customer’s purges. In that initial post, we explained how our purge system worked and the design constraints we found when scaling. We outlined how after more than a decade, we had outgrown our purge system and started building an entirely new purge system, and provided purge performance benchmarking that users experienced at the time. We set ourselves a lofty goal: to be the fastest.
Today, we’re excited to share that we’ve built the fastest cache purge in the industry. We now offer a global purge latency for purge by tags, hostnames, and prefixes of less than 150ms on average (P50), representing a 90% improvement since May 2022. Users can now purge from anywhere, (almost) instantly. By the time you hit enter on a purge request and your eyes blink, the file is now removed from our global network — including data centers in 330 cities and 120+ countries.
But that’s not all. It wouldn’t be Birthday Week if we stopped at just being the fastest purge. We are also announcing that we’re opening up more purge options to Free, Pro, and Business plans. Historically, only Enterprise customers had access to the full arsenal of cache purge methods supported by Cloudflare, such as purge by cache-tags, hostnames, and URL prefixes. As part of rebuilding our purge infrastructure, we’re not only fast but we are able to scale well beyond our current capacity. This enables more customers to use different types of purge. We are excited to offer these new capabilities to all plan types once we finish rolling out our new purge infrastructure, and expect to begin offering additional purge capabilities to all plan types in early 2025.
Why cache and purge?
Caching content is like pulling off a spectacular magic trick. It makes loading website content lightning-fast for visitors, slashes the load on origin servers and the cost to operate them, and enables global scalability with a single button press. But here’s the catch: for the magic to work, caching requires predicting the future. The right content needs to be cached in the right data center, at the right moment when requests arrive, and in the ideal format. This guarantees astonishing performance for visitors and game-changing scalability for web properties.
Cloudflare helps make this caching magic trick easy. But regular users of our cache know that getting content into cache is only part of what makes it useful. When content is updated on an origin, it must also be updated in the cache. The beauty of caching is that it holds content until it expires or is evicted. To update the content, it must be actively removed and updated across the globe quickly and completely. If data centers are not uniformly updated or are updated at drastically different times, visitors risk getting different data depending on where they are located. This is where cache “purging” (also known as “cache invalidation”) comes in.
One-to-many purges on Cloudflare
Back in part 2 of the blog series, we touched on how there are multiple ways of purging cache: by URL, cache-tag, hostname, URL prefix, and “purge everything”, and discussed a necessary distinction between purging by URL and the other four kinds of purge — referred to as flexible purges — based on the scope of their impact.
The reason flexible purge isn’t also fully coreless yet is because it’s a more complex task than “purge this object”; flexible purge requests can end up purging multiple objects – or even entire zones – from cache. They do this through an entirely different process that isn’t coreless compatible, so to make flexible purge fully coreless we would have needed to come up with an entirely new multi-purge mechanism on top of redesigning distribution. We chose instead to start with just purge by URL, so we could focus purely on the most impactful improvements, revamping distribution, without reworking the logic a data center uses to actually remove an object from cache.
We said our next steps included a redesign of flexible purges at Cloudflare, and today we’d like to walk you through the resulting system. But first, a brief history of flexible cache purges at Cloudflare and elaboration on why the old flexible purge system wasn’t “coreless compatible”.
Just in time
“Cache” within a given data center is made up of many machines, all contributing disk space to store customer content. When a request comes in for an asset, the URL and headers are used to calculate a cache key, which is the filename for that content on disk and also determines which machine in the datacenter that file lives on. The filename is the same for every data center, and every data center knows how to use it to find the right machine to cache the content. A purge request for a URL (plus headers) therefore contains everything needed to generate the cache key — the pointer to the response object on disk — and getting that key to every data center is the hardest part of carrying out the purge.
Purging content based on response properties has a different hardest part. If a customer wants to purge all content with the cache-tag “foo”, for example, there’s no way for us to generate all the cache keys that will point to the files with that cache-tag at request time. Cache-tags are response headers, and the decision of where to store a file is based on request attributes only. To find all files with matching cache-tags, we would need to look at every file in every cache disk on every machine in every data center. That’s thousands upon thousands of machines we would be scanning for each purge-by-tag request. There are ways to avoid actually continuously scanning all disks worldwide (foreshadowing!) but for our first implementation of our flexible purge system, we hoped to avoid the problem space altogether.
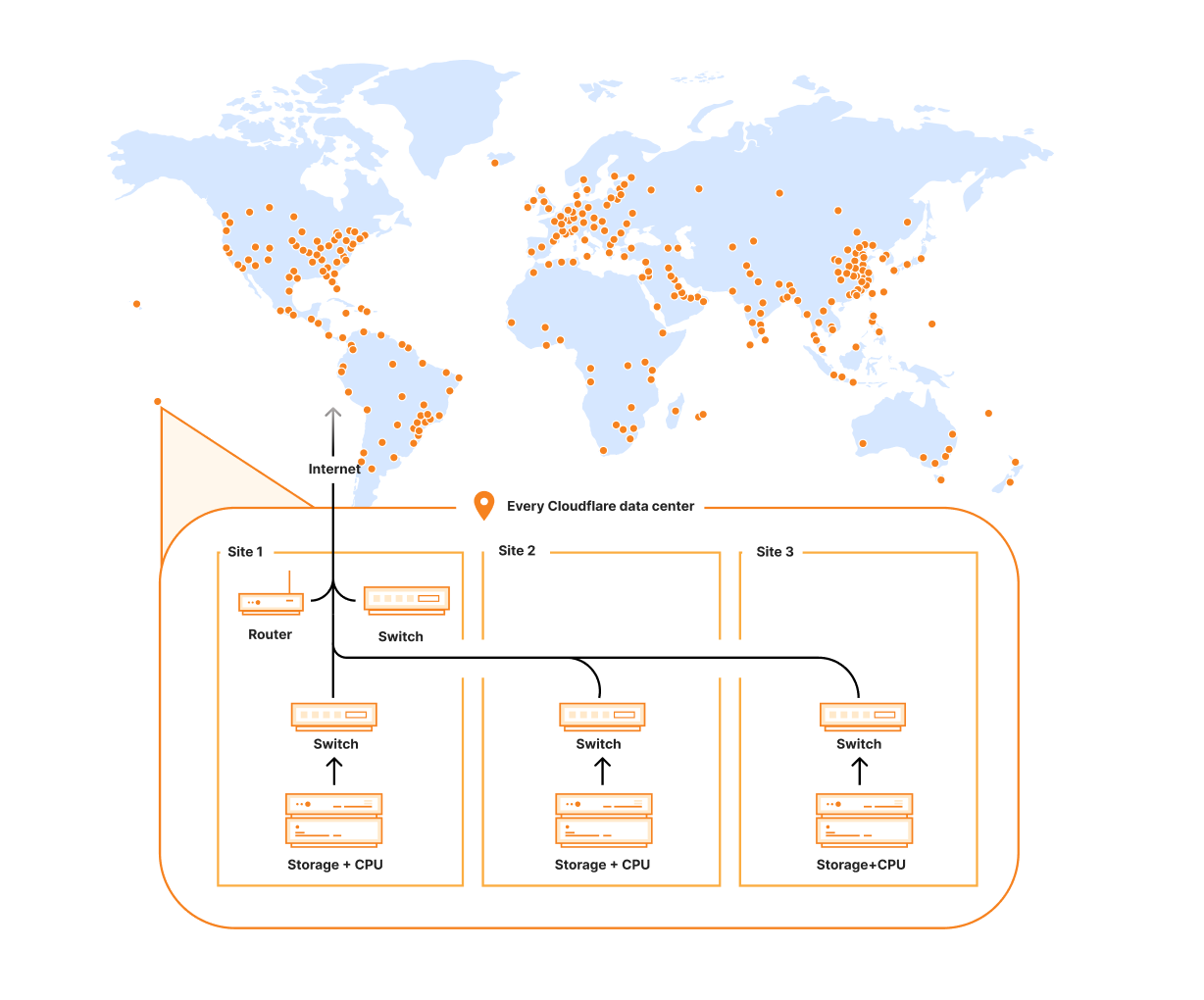
An alternative approach to going to every machine and looking for all files that match some criteria to actively delete from disk was something we affectionately referred to as “lazy purge”. Instead of deleting all matching files as soon as we process a purge request, we wait to do so when we get an end user request for one of those files. Whenever a request comes in, and we have the file in cache, we can compare the timestamp of any recent purge requests from the file owner to the insertion timestamp of the file we have on disk. If the purge timestamp is fresher than the insertion timestamp, we pretend we didn’t find the file on disk. For this to work, we needed to keep track of purge requests going back further than a data center’s maximum cache eviction age to be sure that any file a customer sends a matching flex purge to clear from cache will either be naturally evicted, or forced to cache MISS and get refreshed from the origin. With this approach, we just needed a distribution and storage system for keeping track of flexible purges.
Purge looks a lot like a nail
At Cloudflare there is a lot of configuration data that needs to go “everywhere”: cache configuration, load balancer settings, firewall rules, host metadata — countless products, features, and services that depend on configuration data that’s managed through Cloudflare’s control plane APIs. This data needs to be accessible by every machine in every datacenter in our network. The vast majority of that data is distributed via a system introduced several years ago called Quicksilver. The system works very, very well (sub-second p99 replication lag, globally). It’s extremely flexible and reliable, and reads are lightning fast. The team responsible for the system has done such a good job that Quicksilver has become a hammer that when wielded, makes everything look like a nail… like flexible purges.
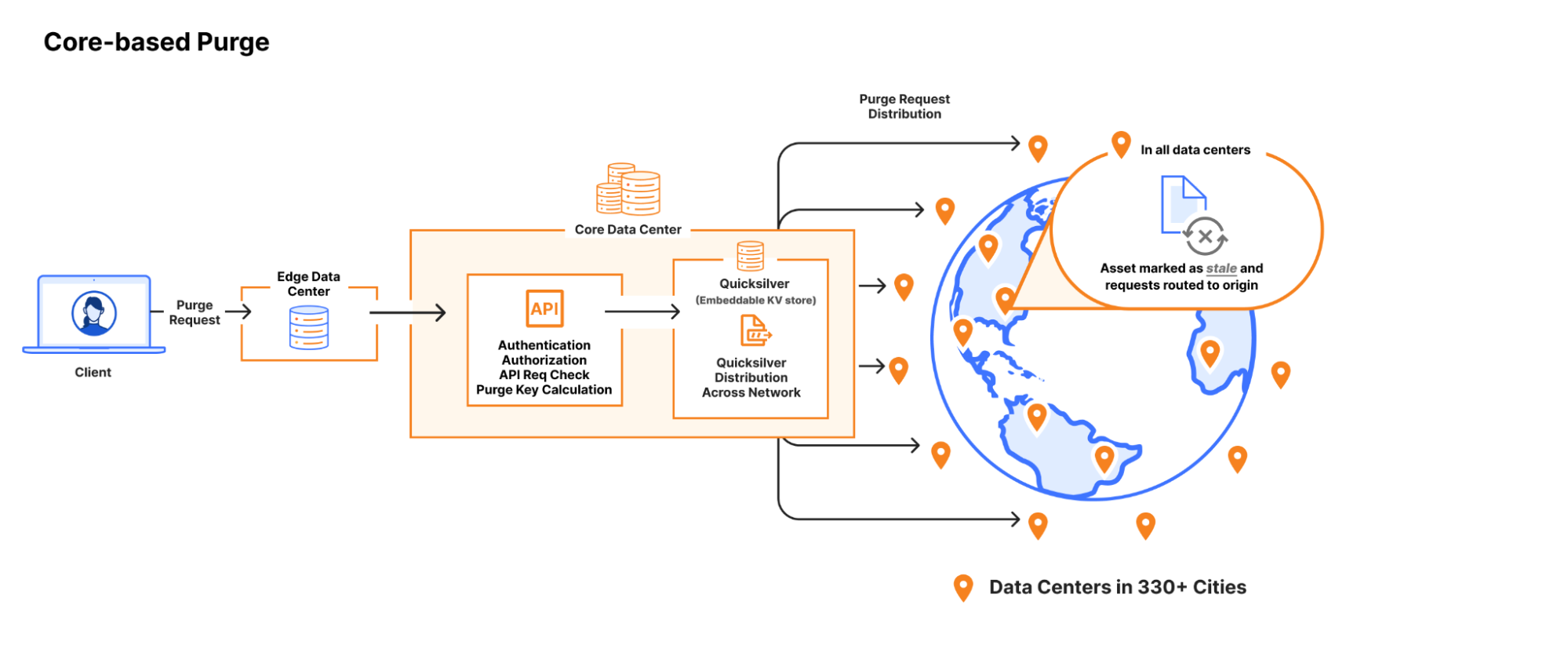
Core-based purge request entering a data center and getting backhauled to a core data center where Quicksilver distributes the request to all network data centers (hub and spoke).
Our first version of the flexible purge system used Quicksilver’s spoke-hub distribution to send purges from a core data center to every other data center in our network. It took less than a second for flexible purges to propagate, and once in a given data center, the purge key lookups in the hot path to force cache misses were in the low hundreds of microseconds. We were quite happy with this system at the time, especially because of the simplicity. Using well-supported internal infrastructure meant we weren’t having to manage database clusters or worry about transport between data centers ourselves, since we got that “for free”. Flexible purge was a new feature set and the performance seemed pretty good, especially since we had no predecessor to compare against.
Victims of our own success
Our first version of flexible purge didn’t start showing cracks for years, but eventually both our network and our customer base grew large enough that our system was reaching the limits of what it could scale to. As mentioned above, we needed to store purge requests beyond our maximum eviction age. Purge requests are relatively small, and compress well, but thousands of customers using the API millions of times a day adds up to quite a bit of storage that Quicksilver needed on each machine to maintain purge history, and all of that storage cut into disk space we could otherwise be using to cache customer content. We also found the limits of Quicksilver in terms of how many writes per second it could handle without replication slowing down. We bought ourselves more runway by putting Kafka queues in front of Quicksilver to buffer and throttle ourselves to even out traffic spikes, and increased batching, but all of those protections introduced latency. We knew we needed to come up with a solution without such a strong correlation between usage and operational costs.
Another pain point exposed by our growing user base that we mentioned in Part 2 was the excessive round trip times experienced by customers furthest away from our core data centers. A purge request sent by a customer in Australia would have to cross the Pacific Ocean and back before local customers would see the new content.
To summarize, three issues were plaguing us:
-
Latency corresponding to how far a customer was from the centralized ingest point.
-
Latency due to the bottleneck for writes at the centralized ingest point.
-
Storage needs in all data centers correlating strongly with throughput demand.
Coreless purge proves useful
The first two issues affected all types of purge. The spoke-hub distribution model was problematic for purge-by-URL just as much as it was for flexible purges. So we embarked on the path to peer-to-peer distribution for purge-by-URL to address the latency and throughput issues, and the results of that project were good enough that we wanted to propagate flexible purges through the same system. But doing so meant we’d have to replace our use of Quicksilver; it was so good at what it does (fast/reliable replication network-wide, extremely fast/high read throughput) in large part because of the core assumption of spoke-hub distribution it could optimize for. That meant there was no way to write to Quicksilver from “spoke” data centers, and we would need to find another storage system for our purges.
Flipping purge on its head
We decided if we’re going to replace our storage system we should dig into exactly what our needs are and find the best fit. It was time to revisit some of our oldest conclusions to see if they still held true, and one of the earlier ones was that proactively purging content from disk would be difficult to do efficiently given our storage layout.
But was that true? Or could we make active cache purge fast and efficient (enough)? What would it take to quickly find files on disk based on their metadata? “Indexes!” you’re probably screaming, and for good reason. Indexing files’ hostnames, cache-tags, and URLs would undoubtedly make querying for relevant files trivial, but a few aspects of our network make it less straightforward.
Cloudflare has hundreds of data centers that see trillions of unique files, so any kind of global index — even ignoring the networking hurdles of aggregation — would suffer the same type of bottlenecking issues with our previous spoke-hub system. Scoping the indices to the data center level would be better, but they vary in size up to several hundred machines. Managing a database cluster in each data center scaled to the appropriate size for the aggregate traffic of all the machines was a daunting proposition; it could easily end up being enough work on its own for a separate team, not something we should take on as a side hustle.
The next step down in scope was an index per machine. Indexing on the same machine as the cache proxy had some compelling upsides:
-
The proxy could talk to the index over UDS (Unix domain sockets), avoiding networking complexities in the hottest paths.
-
As a sidecar service, the index just had to be running anytime the machine was accepting traffic. If a machine died, so would the index, but that didn’t matter, so there wasn’t any need to deal with the complexities of distributed databases.
-
While data centers were frequently adding and removing machines, machines weren’t frequently adding and removing disks. An index could reasonably count on its maximum size being predictable and constant based on overall disk size.
But we wanted to make sure it was feasible on our machines. We analyzed representative cache disks from across our fleet, gathering data like the number of cached assets per terabyte and the average number of cache-tags per asset. We looked at cache MISS, REVALIDATED, and EXPIRED rates to estimate the required write throughput.
After conducting a thorough analysis, we were convinced the design would work. With a clearer understanding of the anticipated read/write throughput, we started looking at databases that could meet our needs. After benchmarking several relational and non-relational databases, we ultimately chose RocksDB, a high-performance embedded key-value store. We found that with proper tuning, it could be extremely good at the types of queries we needed.
Putting it all together
And so CacheDB was born — a service written in Rust and built on RocksDB, which operates on each machine alongside the cache proxy to manage the indexing and purging of cached files. We integrated the cache proxy with CacheDB to ensure that indices are stored whenever a file is cached or updated, and they’re deleted when a file is removed due to eviction or purging. In addition to indexing data, CacheDB maintains a local queue for buffering incoming purge operations. A background process reads purge operations in the queue, looking up all matching files using the indices, and deleting the matched files from disk. Once all matched files for an operation have been deleted, the process clears the indices and removes the purge operation from the queue.
To further optimize the speed of purges taking effect, the cache proxy was updated to check with CacheDB — similar to the previous lazy purge approach — when a cache HIT occurs before returning the asset. CacheDB does a quick scan of its local queue to see if there are any pending purge operations that match the asset in question, dictating whether the cache proxy should respond with the cached file or fetch a new copy. This means purges will prevent the cache proxy from returning a matching cached file as soon as a purge reaches the machine, even if there are millions of files that correspond to a purge key, and it takes a while to actually delete them all from disk.
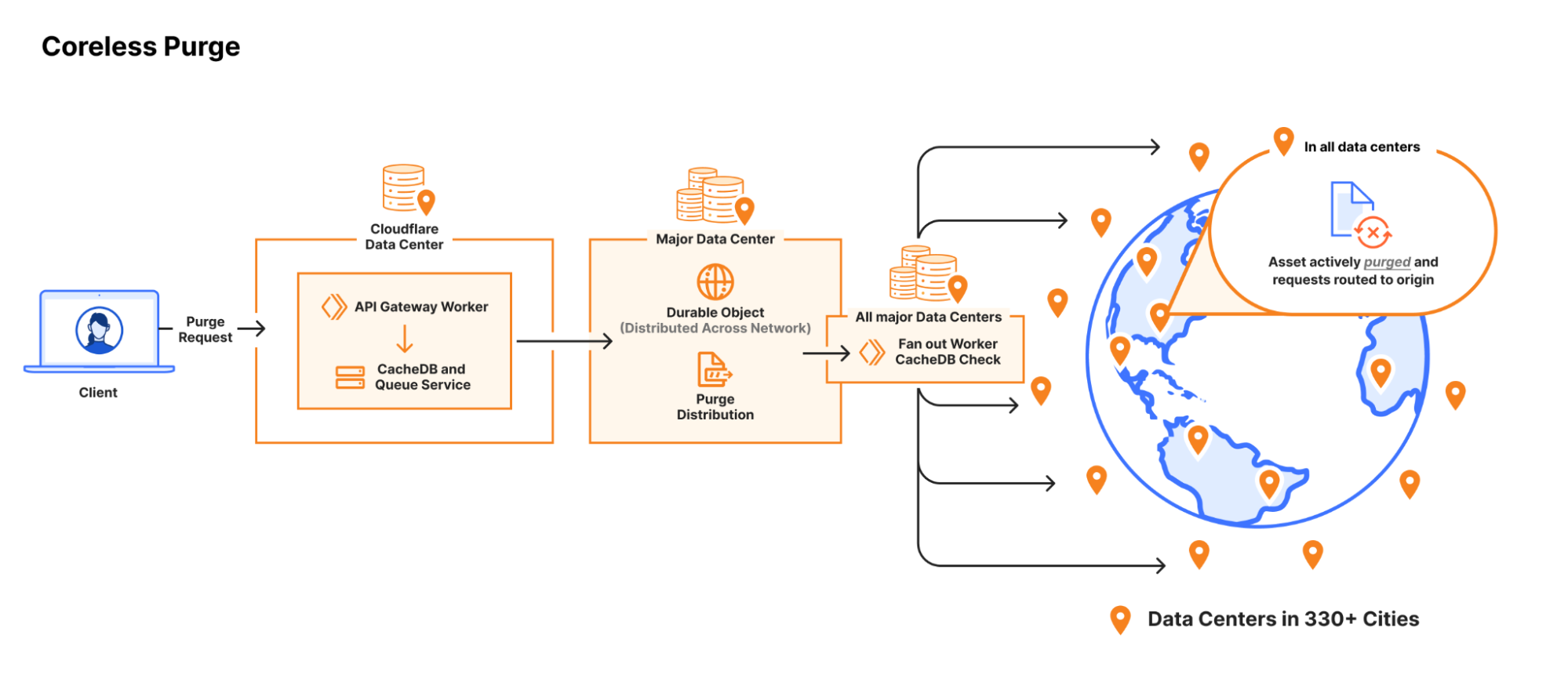
Coreless purge using CacheDB and Durable Objects to distribute purges without needing to first stop at a core data center.
The last piece to change was the distribution pipeline, updated to broadcast flexible purges not just to every data center, but to the CacheDB service running on every machine. We opted for CacheDB to handle the last-mile fan out of machine to machine within a data center, using consul to keep each machine informed of the health of its peers. The choice let us keep the Workers largely the same for purge-by-URL (more here) and flexible purge handling, despite the difference in termination points.
The payoff
Our new approach reduced the long tail of the lazy purge, saving 10x storage. Better yet, we can now delete purged content immediately instead of waiting for the lazy purge to happen or expire. This new-found storage will improve cache retention on disk for all users, leading to improved cache HIT ratios and reduced egress from your origin.
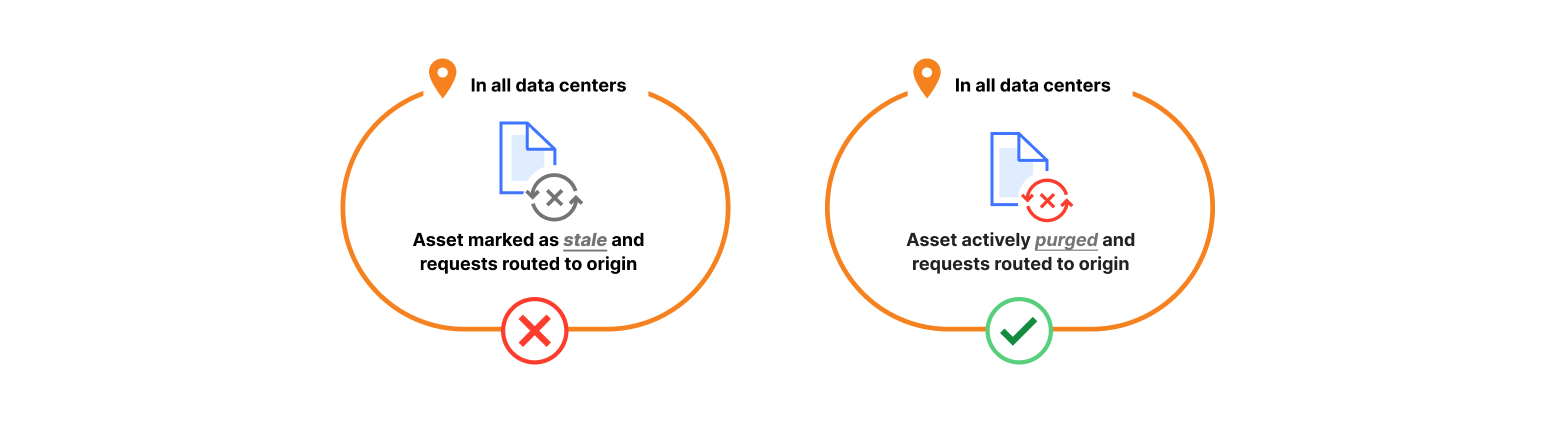
The shift from lazy content purging (left) to the new Coreless Purge architecture allows us to actively delete content (right). This helps reduce storage needs and increase cache retention times across our service.
With the new coreless cache purge, we can now get a purge request into any datacenter, distribute the keys to purge, and instantly purge the content from the cache database. This all occurs in less than 150 milliseconds on P50 for tags, hostnames, and prefix URL, covering all 330 cities in 120+ countries.
Benchmarks
To measure Instant Purge, we wanted to make sure that we were looking at real user metrics — that these were purges customers were actually issuing and performance that was representative of what we were seeing under real conditions, rather than marketing numbers.
The time we measure represents the period when a request enters the local datacenter, and ends with when the purge has been executed in every datacenter. When the local data center receives the request, one of the first things we do is to add a timestamp to the purge request. When all data centers have completed the purge action, another timestamp is added to “stop the clock.” Each purge request generates this performance data, and it is then sent to a database for us to measure the appropriate quantiles and to help us understand how we can improve further.
In August 2024, we took purge performance data and segmented our collected data by region based on where the local data center receiving the request was located.
|
Region |
P50 Aug 2024 (Coreless) |
P50 May 2022 (Core-based) |
Improvement |
|
Africa |
303ms |
1,420ms |
78.66% |
|
Asia Pacific Region (APAC) |
199ms |
1,300ms |
84.69% |
|
Eastern Europe (EEUR) |
140ms |
1,240ms |
88.70% |
|
Eastern North America (ENAM) |
119ms |
1,080ms |
88.98% |
|
Oceania |
191ms |
1,160ms |
83.53% |
|
South America (SA) |
196ms |
1,250ms |
84.32% |
|
Western Europe (WEUR) |
131ms |
1,190ms |
88.99% |
|
Western North America (WNAM) |
115ms |
1,000ms |
88.5% |
|
Global |
149ms |
1,570ms |
90.5% |
Note: Global latency numbers on the core-based measurements (May 2022) may be larger than the regional numbers because it represents all of our data centers instead of only a regional portion, so outliers and retries might have an outsized effect.
What’s next?
We are currently wrapping up the roll-out of the last throughput changes which allow us to efficiently scale purge requests. As that happens, we will revise our rate limits and open up purge by tag, hostname, and prefix to all plan types! We expect to begin rolling out the additional purge types to all plans and users beginning in early 2025.
In addition, in the process of implementing this new approach, we have identified improvements that will shave a few more milliseconds off our single-file purge. Currently, single-file purges have a P50 of 234ms. However, we want to, and can, bring that number down to below 200ms.
If you want to come work on the world’s fastest purge system, check out our open positions.
